The O word: do you really need an ontology? The Year of the Graph Newsletter Vol. 17, November / October 2019

How do you manage your enterprise data in order to keep track of it and be able to build and operate useful applications? This is a key question all data managements systems are trying to address, and knowledge graphs, graph databases and graph analytics are no different.
What is different about knowledge graphs is that they may actually be the most elaborate and holistic way to manage your enterprise domain knowledge.
For people who have been into knowledge graphs and ontologies, this is old news. What is new is that more and more people today seem to be listening, rather than dismissing ontology as too complex, unrealistic, academic etc.
These last couple of months we’ve seen a flurry of activity on all of these technologies. From organizational culture and adoption to events, research and tutorials, it’s all here.
So, who’s afraid of the O word? Maybe what you need is an ontology? Mark Hall from Morgan Stanley thinks so. Hall paints a very vivid picture of the enterprise data management landscape, and addresses why ontology has been overlooked for so long. On a related note: Kurt Cagle on Forbes discusses knowledge bases

Did You Know What You Really Need is an Ontology?
Building your own enterprise knowledge base, supported by a robust representational data model will give you the building blocks to be self-determinate, have an insightful view into your data and not be beholden to someone else’s ability to innovate. What you need is an Ontology.
Case in point: some use cases for ontologies and knowledge graphs, from PepsiCo and the Dutch Kadaster.

Agricultural ontologies in use: new crops and traits in the crop ontology
In conjunction with their collaborators at NIAB, PepsiCo created a new oat ontology. They have been working to incorporate this new ontology into Crop Ontology so that all working with oats have the opportunity to utilize consistent nomenclature and standards.
It’s been an eventful period for graph databases. Neo4j just launched Aura, its database as a service offering which it says will truly bring graph databases to the mass market. Ontotext open-sourced part of its GraphDB product. Amazon’s Neptune, Microsoft’s Cosmos DB, and ArangoDB added new capabilities, Redis debuted on Google Cloud, and Apache Rya graduated to a top level project.

Graph for the mass market: Neo4j launches Aura on Google Cloud
Neo4j Aura, a fully managed native graph Database as a Service (DBaaS), has just been released. The key points Neo4j emphasizes about Aura are always-on availability, on-demand scalability, and a developer-first approach. With Aura, Neo4j, and graph databases, enter the cloud era.
Graph databases, knowledge graphs, and AI. These are some of the tools for those who use the relationships, meaning and context in Data to achieve great things. Connected Data London is where data, people and ideas connect, and CDL2019 was a blast.
Keynotes on the Search for the Universal Data Model by Uber Research Scientist and Apache Tinkerpop co-founder Joshua Shinavier and the Biggest Knowledge Graph at work ever created by Microsoft AI Manager David Gorena, and a who is who of graph databases, analytics, AI and knowledge graphs. If you missed it, here’s brief recap with pointers to the event’s highlights.
Connected Data London 2019: learning and growing together
Top speakers and sponsors, an energetic and engaged community, and organizers who are an active part of the community. This is what makes Connected Data London what it is: a shared learning experience for practitioners, thought leaders and newcomers to the exciting intersection of AI, Knowledge Graphs, Graph Databases, Linked Data and Semantic Tech.
Another important event in this space is ISWC, where lots of new research which later finds its way into knowledge graph applications first sees the light, as well as use cases by the likes of Bosch and Pinterest. For more details, trip reviews to the rescue. Here’s one from data.world’s Juan Sequeda and one from W3C’s Armin Haller.
Sequeda also keynoted, presented a brief history of knowledge graphs, and a Pay-as-you-go Methodology to Design and Build Knowledge Graphs. In Olaf Hartig’s keynote, the focus was on optimizing query processing for response time in web-based scenarios, which is key for enabling a decentralized web of data. Hartig started this line of research 10 years ago, and was awarded for this by ISWC.

A Pay-as-you-go Methodology to Design and Build Knowledge Graphs
Even though the research and industry community has provided evidence that semantic technologies works in the real world, our experience is that there continues to be a major challenge: the engineering of ontologies and mappings covering enterprise databases containing thousands of tables with tens of thousands of attributes.
More knowledge graph research, this time from Facebook. A new method to improve the performance of long-form question answering (QA) systems by enabling them to search relevant text more efficiently.
This method builds on Facebook AI’s work on long-form QA a natural language processing (NLP) research task where models must answer a natural language question, such as “What is Albert Einstein famous for?” by using the top 100 web search results.

Improving long-form question answering by compressing search results
Though the answer is typically present in results, sequence-to-sequence (seq2seq) models struggle with analyzing such a large amount of data, which requires processing hundreds of thousands of words. By compressing text into a knowledge graph and introducing a more fine-grained attention mechanism, this technique allows models to use the entirety of web search results to interpret relevant information.
Microsoft, too, made a knowledge graph related announcement in its Ignite event: Project Cortex, a knowledge-management service for Office 365. This new knowledge-management service is the first major new Microsoft 365 cloud service that Microsoft has introduced since 2017. The service is meant to help organize businesses’ content that’s accessible in SharePoint and make it available to users in a proactive way.

Meet Project Cortex, Office 365 knowledge-management service
Project Cortex will create and update new topic pages and knowledge centers that are meant to act like wikis. Topic cards will be available to users in Outlook, Teams and Office. Cortex builds on top of Microsoft cognitive services for image and text recognition, forms processing and machine teaching.
Gartner just published its 2019 Magic Quadrant for Metadata Management Solutions. For the first time, 2 vendors which rely on semantic technology and knowledge graphs are in the Magic Quadrant: data.world and the Semantic Web Company. This highlights the applicability of this technology in the real world, and we expect to see more of this going forward.

Magic Quadrant for Metadata Management Solutions
Demand arising from a variety of data and analytics initiatives drives strategic requirements for metadata management solutions. This Magic Quadrant will help data and analytics leaders find the most appropriate vendor and solution for their organizational needs.
The graph analytics market is estimated to be worth $2,522 million by 2024, at a Compound Annual Growth Rate of 34.0%. Being in a good position to address this market sounds like a good idea. Nvidia says it’s on a mission to provide multi-GPU graph analytics for billion/trillion scale graphs.
Nvidia is making progress with its cuGraph open source library. Here is an example of 4 of these algorithms that have already been delivered. These algorithms work on a single CPU, but Nvidia just released a single-node multi-GPU version of PageRank too.
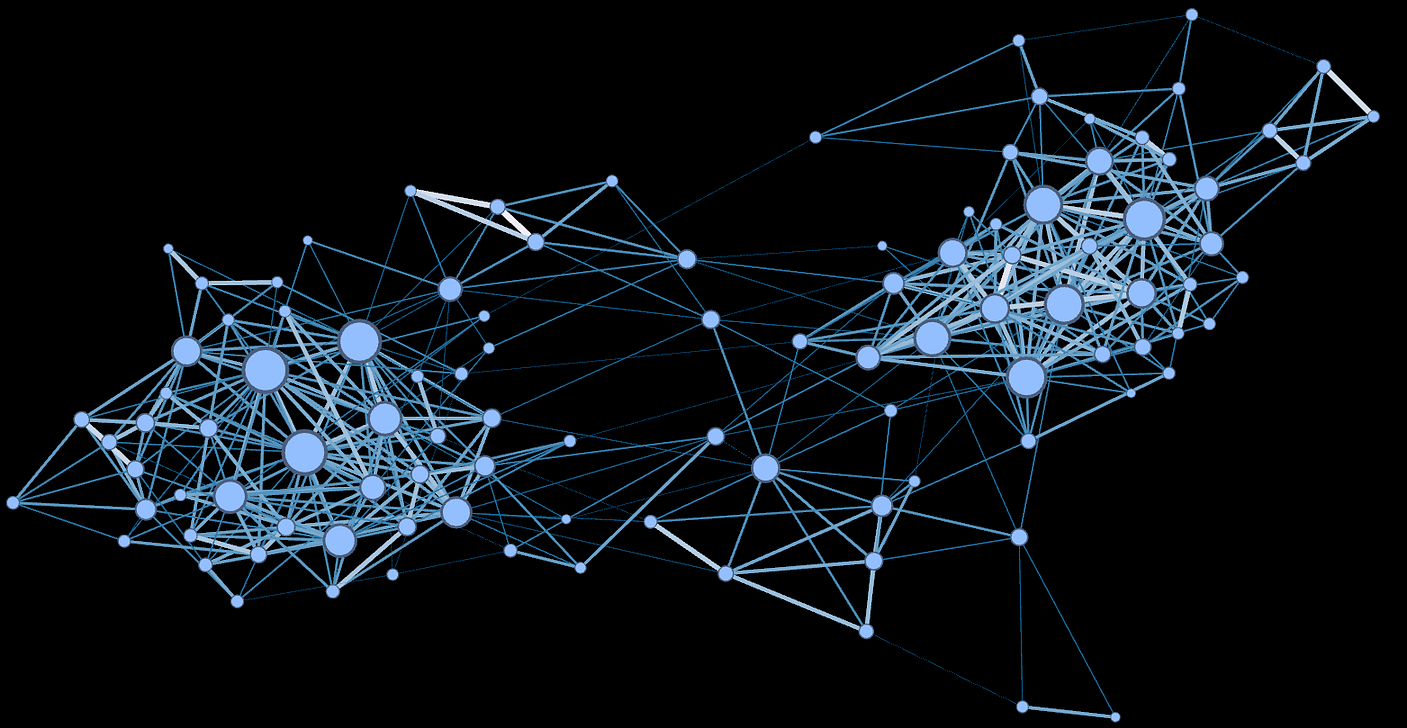
RAPIDS cuGraph : multi-GPU PageRank
Experimental results show that an end-to-end pipeline involving the new multi-GPU PageRank is on average 80x faster than Apache Spark when comparing one DGX-2 vs 100 Spark nodes on a 300GB dataset. At the CUDA level, a graph of this size is traversed at a speed of 38 billion edges per second on a single node.
Wrapping up with some tutorials and examples. Converting JSON to RDF, which highlights RDF’s potential for data integration. Querying Wikidata (or any other Linked Data endppoint) from within Rstats, and using Jupyter Notebooks. And last but not least, Graph Data Modeling of Categorical Variables, and Sentiment Analysis on Twitter Data.

Sentiment Analysis on Twitter Data Using Neo4j and Google Cloud
The first thing we’ll need to do is to design a data model for analyzing the sentiments and influences of users on Twitter. This diagram is the graph data model that we will use to import, analyze, and query data from Twitter.
Related posts:
 Graph Database market update, September 2024: Google Cloud Spanner Graph, Amazon Neptune, Neo4j
Graph Database market update, September 2024: Google Cloud Spanner Graph, Amazon Neptune, Neo4j
 Graphs in the cloud. The Year of the Graph Newsletter Vol. 12, April 2019
Graphs in the cloud. The Year of the Graph Newsletter Vol. 12, April 2019
 The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
 Graph gets funding. The Year of the Graph Newsletter Vol. 7, November 2018
Graph gets funding. The Year of the Graph Newsletter Vol. 7, November 2018


Has one comment to “The O word: do you really need an ontology? The Year of the Graph Newsletter Vol. 17, November / October 2019”
[…] “The O word: do you really need an ontology?” was published in 2019. Before GenAI was a thing, Mark Hall made a compelling case for ontologies and offered an explanation as to why isn’t everyone doing this. […]