Knowledge graphs, AI, and interoperability. The Year of the Graph Newsletter Vol. 10, February 2019

Knowledge graphs are spreading everywhere: from Airbnb and eBay to Alexa, and from using JSON-LD on the web for better SEO to leveraging taxonomy to define AI. Combining knowledge graphs and machine learning, benchmarking graph databases, and W3C initiative for interoperability shaping up. January 2019 has been a lively month in the graph landscape.
A brief history of semantics and knowledge graphs, context and how to leverage it, as well as some key architectures in the semantic space: knowledge graphs, smart data hubs, semantic data catalogs, metadata managers and smart contracts. By Kurt Kagle from Semantical LLC.
The Semantic Zoo – Smart Data Hubs, Knowledge Graphs and Data Catalogs
To the extent that you can separate context from data storage, you have the means to widen the lens, so to speak, going from something that lets you view or look at only one aspect of the data space to one that lets you see it from all possible perspectives. This is what semantics gives you.
What is the low-hanging fruit, or the most popular form, of knowledge graphs? Web content annotations, which can turn every web page to a part of the big knowledge graph that is the web. Here Aaron Bradley from Electronic Arts brings the work of Yoast’s Jono Alderson to the fore. Yoast is one of the leading experts in SEO, and what Alderson has to share is highly relevant.
Bonus track: this survey from Bradley which seems to settle the score on what people prefer to use to annotate: 80% go for JSON-LD.

A general specification for implementing structured markup (using schema.org and JSON-LD)
The author of this Google doc, Jono Alderson, plans to make it “into a little website with structured/interlinked guidelines” but it’s worth reading now > A general specification for implementing structured markup (using #schema.org and JSON-LD).
Another perspective on knowledge graphs: part inspirational personal journey, part grounded technology and science use case, Elsevier’s Helena Deus describes what a knowledge graph can do for oncology.

What can a knowledge graph do for oncology?
To explain how a knowledge graph could be useful for oncology, consider the story of young Esmeralda Pineda (Ezzy). The treatment was a huge success. Ezzy’s story is quite unique and it can be represented as a knowledge graph where each event, state or real world entity can be represented as a node and the relationships between them as edges.
Deus also touches on the relationships between knowledge graphs and deep learning. Deep learning is what many people associate with AI today. But as shown in this analysis by Karen Hao from MIT Technology Review, maybe the era of deep learning will come to an end. The biggest shift found was a transition away from knowledge-based systems by the early 2000s.
But as Pedro Domingos put it, “If somebody had written in 2011 that [deep learning] was going to be on the front page of newspapers and magazines in a few years, we would’ve been like, ‘Wow, you’re smoking something really strong,’”. Maybe the time for the return of knowledge-based systems has come.
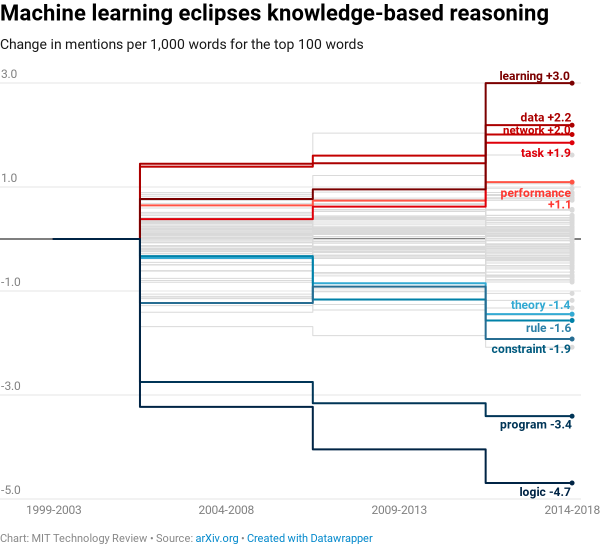
We analyzed 16,625 papers to figure out where AI is headed next
The biggest shift we found was a transition away from knowledge-based systems by the early 2000s. These computer programs are based on the idea that you can use rules to encode all human knowledge. In their place, researchers turned to machine learning—the parent category of algorithms that includes deep learning.
For all its success, deep learning is not really all there is an AI. In fact, there is not even such a thing as a widely accepted definition of AI. Tellingly, however, applying a combination of taxonomy and machine learning, has helped researchers from Elsevier get better results in defining AI:

“Nobody agrees on what AI is” – How Elsevier’s report used AI to define the undefinable
In contrast with manually developed taxonomies of research areas, which inevitably end up reflecting the specific viewpoints of the experts involved in the process, this characterization is data-driven, using machine learning and text-mining techniques to classify documents and identify the keywords.
One of the problems with knowledge graphs is scale. Not so much in terms of performance, but more in terms of building and maintaining them. Amit Sheth from the Ohio Center of Excellence in Knowledge-enabled Computing has been one of the pioneers in knowledge graphs. Here he shares his experience from 2000, when it seemed to take 10,000 people to build a (big) knowledge graph. This still seems to apply to Alexa’s knowledge graph today.

Why do these Knowledge Graphs need 10,000 pairs of hands?
It seems the rule of thumb for how many pairs of hands it takes for building such KG and related ecosystem is 10,000 – an astounding number. This article confirms the number for Alexa. Earlier, through conversations with reliable sources, I had heard the that around the same number of people were involved in building and maintaining Google KG.
Scale does not seem to be a problem for Airbnb. After sharing initial steps towards building their knowledge graph, Airbnb engineers are back with more details.
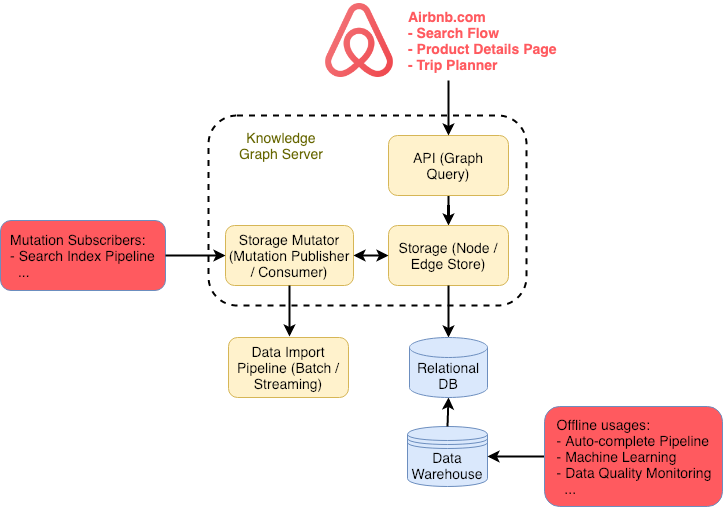
Contextualizing Airbnb by Building Knowledge Graph
An introduction to Airbnb’s knowledge graph, which helps us categorize our inventory and deliver useful travel context to our users.
More heavyweights using knowledge graphs: eBay researchers share how to perform explainable reasoning over knowledge graphs for recommendations
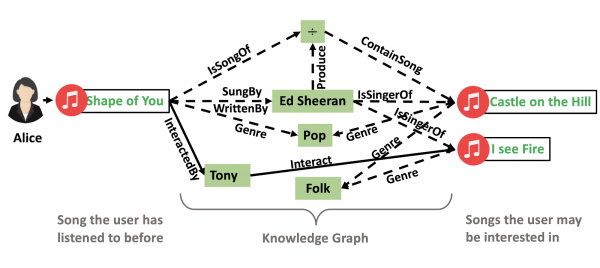
Explainable Reasoning over Knowledge Graphs for Recommendation
Incorporating knowledge graphs into recommender systems has attracted increasing attention in recent years. By exploring the interlinks within a knowledge graph, the connectivity between users and items can be discovered as paths, which provide rich and complementary information to user-item interactions.
In the end, it may well be the case that knowledge graphs need machine learing to scale, as much as machine learning needs knowledge graphs to infuse meaning. Here Kalev Leetaru makes the case for the latter on Forbes.

Why Machine Learning Needs Semantics Not Just Statistics
When humans learn, they connect the patterns they identify to high order semantic abstractions of the underlying objects and activities. In turn, our background knowledge and experiences give us the necessary context to reason about those patterns and identify the ones most likely to represent robust actionable knowledge.
Interestingly, there are ways to combine machine learning and knowledge graphs / semantics. Here Bob DuCharme describes a project that brings RDF technology and distributional semantics together, letting SPARQL query logic take advantage of entity similarity as rated by machine learning models.

Querying machine learning distributional semantics with SPARQL
I recently learned of a fascinating project that brings RDF technology and distributional semantics together, letting our SPARQL query logic take advantage of entity similarity as rated by machine learning models.
This has been an ongoing trend for graph databases. Ontotext’s GraphDB 8.8 was just released, and it now allows users to perform semantic similarity searches based on embedding of relationships in a graph in a highly-scalable vector space model. It also enables users to query JSON-LD from MongoDB, plus some more improvements.

Ontotext’s GraphDB 8.8.0 Enriches the Knowledge Graph Experience
Ontotext has just released GraphDB 8.8.0 – the latest version of its signature semantic graph database, which now offers MongoDB integration for large-scale metadata management, new semantic similarity search, based on graph embedding, and faster and more flexible full-text search (FTS) connectors.
Alok Prasad from Cambridge Semantics briefly reviews what has been the first in the series of the years of the Graph – 2018
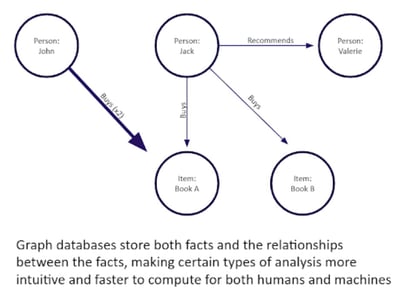
The Year of the Graph in Review & the Emergence of Graph OLAP Databases
In 2018, industry analysts declared 2018 as the year of the graph. As we move into 2019, it is worth reflecting how the graph market has evolved.
Graph is on the front page. Craig Stedman from TechTarget with an intro to graph databases.

Graph software shines spotlight on data relationships
This handbook looks at what graph databases can do and when organizations might want to consider using them. In the opening feature, two users discuss their deployment of graph database software and their experiences with the technology. We also detail the different technology options available to prospective graph database users.
Something more involved: How Representative is a SPARQL Benchmark? Muhammad Saleem from AKSW shares an analysis of RDF Triplestore Benchmarks. Must read if you want to understand how benchmarks work, how to compare performance and interpret results.

How Representative is a SPARQL Benchmark? An Analysis of RDF Triplestore Benchmarks
Over recent years, various benchmarks have beenproposed to assess the performance of triplestores across different performance measures. However, choosing the most suitable bench-mark for evaluating triplestores in practical settings is not a trivialtask.
Would you believe there’s a new graph query language on the scene? Gavin Mendel-Gleason from Data Chemist is introducing WOQL, and was hosted in Connected Data London’s first Meetup for 2019. Also, introduction to SKOS (Simple Knowledge Organizatin System) by Phil Stacey from Barratt Homes, and an introduction to Graph Data and Open Source Investigations and Verification by Connected Data London media editor Wais Bashir

The Future of Graph Query Languages & an Introduction to SKOS
The Victors will be Declarative – Exploring the Graph Query Language of the Future. Introduction to simple knowledge organization system (SKOS). Introduction to Graph Data and Open Source Investigations and Verification.
If you think this is getting a bit too much with all those query languages and data formats, you’re not the only one. To quote Ovum analyst Tony Baer: “I always felt graph was better suited being embedded under the hood because it was a strange new database without standards de facto or otherwise. But I’m starting to change my tune — every major data platform provider now has either a graph database or API/engine”.
To address the issue of standards, W3C is organizing a workshop in Berlin this March. Linked Data Orchestration will be there joining the ranks of experts convening to move things forward, with a will on data exchange formats. If you are interested in getting an inside view, join the Connected Data Berlin Meetup. Join us on March the 6th – stay tuned for details.
W3C Workshop on Web Standardization for Graph Data
We’ve had a lot of great input and are looking forward to a rewarding workshop. The following agenda is provisional and we’re seeking your feedback and suggestions for people to lead sessions. We want to focus on discussions relevant to standardisation and plan to keep the number of presentations to a minimum.
Related posts:
 Return of the Graph: Geospatial Knowledge Graphs, Personal Knowledge Graphs, and Evolution. The Year of the Graph Newsletter Vol. 24, Spring 2023
Return of the Graph: Geospatial Knowledge Graphs, Personal Knowledge Graphs, and Evolution. The Year of the Graph Newsletter Vol. 24, Spring 2023
 The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
 Graph-based data science, machine learning and AI. The Year of the Graph Newsletter Vol. 23, Spring 2021
Graph-based data science, machine learning and AI. The Year of the Graph Newsletter Vol. 23, Spring 2021
 Graph Therapy. The Year of the Graph Newsletter Vol. 20, June / May 2020
Graph Therapy. The Year of the Graph Newsletter Vol. 20, June / May 2020

