In Between Years. The Year of the Graph Newsletter Vol. 9, January 2019

In between years, or zwischen den Jahren, is a German expression for the period between Christmas and New Year. This is traditionally a time of year when not much happens, and this playful expression lingers itself in between the literal and the metaphoric. As the first edition of the Year of the Graph newsletter for 2019 is here, a short retrospective may be due in addition to the usual updates.
When we called 2018 the Year of the Graph, we did not have to wait for the Gartners of the world to verify what we saw coming. We can without a doubt say this has been the Year Graphs went mainstream. Things are unfolding, quantity and quality of releases and use cases, and all around progress, is stepping up. So, what follows the Year of the Graph? Why, more Years of the Graph.
In terms of the Newsletter, a small change introduced here is that from now on each edition will come with a title in addition to the month it as released in. Reminder: you can find all previous editions here, and subscribe at the end of each post. In terms of the Report..stay tuned!
Doing reviews and predictions is a favorite pastime for this time of year, so let’s start with a roundup of those. Dan McCreary from Optum Technologies and Giovanni Tumarello from Siren have written some of the most well-received and insightful reviews, while Dataversity compiled a list of insights collected from industry key figures.

Semantic Web and Semantic Technology Trends in 2019
What to expect of Semantic Web and other Semantic Technologies? Knowledge Graphs have gotten a lot of attention as a backbone for Machine Learning, Deep Learning, and AI business use cases.
In Connected Data London, we had the opportunity to host many of those key figures. We learned from them as we all shared insights and knowledge, getting a taste of things to come. Here is our roundup, with links to all the content in case you missed it.

The Future of Data is Connected and Open Minded
Knowledge Graphs, Machine Learning and AI, Linked Data and Semantic Technology and Graph Databases are redefining how data works. Data is redefining how everything works. Connected Data London is the go-to event for the latest developments in these key technologies.
The new year has hardly kicked off, but we already have the first major news. Apache TinkerPop 3.4 is here with a slew of improvements: GraphBinary, a new network serialization format that has shown to be significantly faster than existing options, the SPARQL bridge is officially here, Gremlin Recipes have been expanded with Anti-Patterns, and more. Speaking of recipes, Kelvin Lawrence from IBM has also updated his Practical Gremlin guide.

Apache TinkerPop 3.4.0 Released
Avant-Gremlin Construction #3 for Theremin and Flowers
SPARQL is often dismissed as being impractical, hard to use, etc – like the rest of the Semantic Web. While criticism is warranted, for both technical and non-technical reasons, something seems to be changing. Ruben Verborgh from Ghent University / Inrupt makes valid points on how the Semantic Web offers solutions to hard problems everyone faces, compares SPARQL to GraphQL, and elaborates on how to make this stack accessible, and easier to use.

Designing a Linked Data developer experience
Making decentralized Web app development fun.
Case in point: SPARQL used to measure use of programming paradigms, thanks to Wikidata and its SPARQL endpoint. And some insights derived from SPARQL practitioners. Remember, there is an upcoming W3C workshop on Graph standardization, and we expect to see proposals on how this space can move forward and bridge the gap between RDF and Labeled Property Graphs.
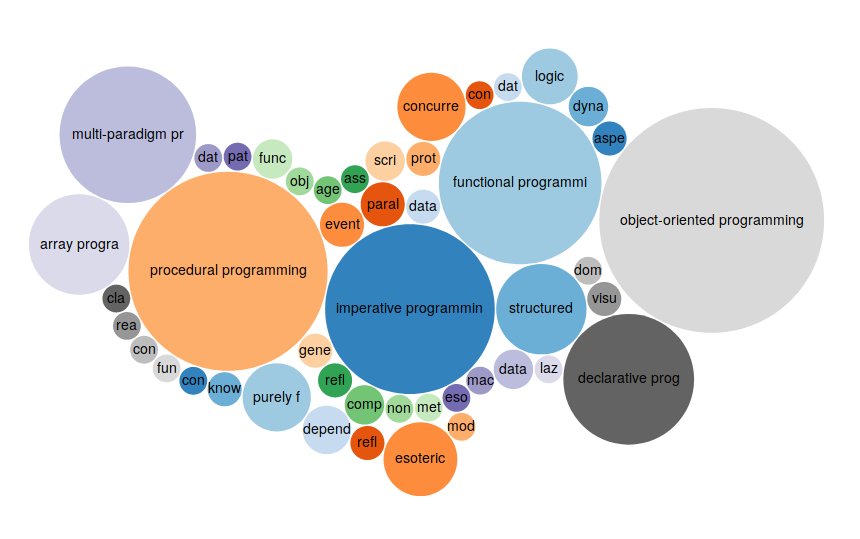
SPARQL is the language used to compare the mentions of all the other programming languages
Some popular programming paradigms, the languages documenting the most number of Software on Wikipeda and the role of http://WikiDP.org, all thanks to Wikidata and its SPARQL endpoint @WikiDgi #swib18
And while we’re discussing query languages: Neo4j just released the first milestone of its GraphQL to Cypher transpiler. What this means is you can now query Neo4j using GraphQL. This may serve as one more entry point to Neo4j for developers coming into the graph ecosystem, as GraphQL’s popularity is on the rise.
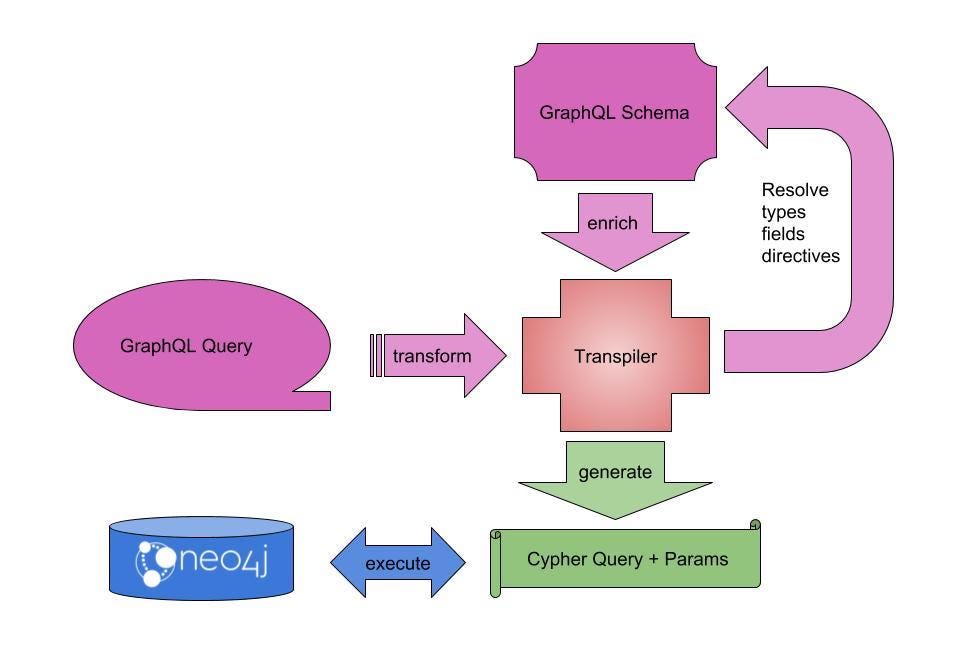
First Milestone Release of the GraphQL to Cypher Transpiler: neo4j-graphql-java
If you want to use GraphQL with Neo4j from any JVM based web application or API, this library helps you to use your schema to transpile the query to Cypher.
CosmosDB, on its part, open-sourced an update of its .NET SDK. But more importantly, CosmosDB lowered its pricing, and added a mechanism to get an accurate cost measure on each Graph API operation. Howard van Rooijen from Endjin elaborates.

Cosmos DB – Request Units charged for processing a Gremlin API request
We’re currently building a Data Governance Platform product that enables UK Financial Services organisations to discover and manage the life-cycle, usage, risk and compliance requirements of data assets across the organisation.
Stardog has also been working on a few things, and although officially Stardog 7 with its new Mastiff engine is still on Beta, features such an IDE and support for Kubernetes seem ready to use.

Announcing Stardog 7 beta
We’re happy to announce the beta release of Stardog 7 which comes with a new storage engine that significantly improves write performance.
With so much choice in RDF stores, doing some testing to see how each performs can help. Angus Addlesee from Wallscope did that. This is no small undertaking, but it’s also far from complete: not all stores included, configurations not optimized, number of experiments too small, and of course, LPG stores not included.
Just goes to show why there are entire projects, such as HOBBIT, dedicated to this effort. Plus, performance is just one of the considerations when evaluating graph databases.

Comparing Linked Data Triplestores
There are many Triplestores available and it is difficult to decide which is best for each use-case. In this article I tie all of my previous posts together and explore the pros and cons of some of the most popular triplestores.
DataStax also released version 6.7 of its multi-model DSE platform. Kafka and Docker integration, operational analytics and more – graph operations will benefit as well. Plus, some useful and generally applicable advice on dealing with super-nodes from DataStax’s Jonathan Lacefield.

Property Graph Modeling with an FU Towards Supernodes – Jonathan Lacefield
Graph databases are receiving a lot of hype these days because of the promise of fast and flexible queries that aren’t possible within either traditional RDBMs or NoSQL stores built on simple/singular access patterns. There are some practical tips and tricks that ensure that your graph database project is going to live up to the hype.
More useful advice: how to avoid Doppelgangers using graph databases, and one graph to find them all by G Data’s Florian Hockmann and Kadir Bölükbasi
How to Avoid Doppelgängers in a Graph Database
In this post, we take a look at the problem of getting duplicate data (the doppelgängers) in a graph database like JanusGraph and discuss different approaches to solve it. We will therefore walk through our experiences with upserts at G DATA and how we improved our upserting process continuously.
Another multi-model graph database with a new release: AgensGraph 2.0. AgensGraph is based on PostgreSQL, offering a graph API and query language (Cypher) on top of it.

Announcing the release of AgensGraph 2.0
AgensGraph is a new generation multi-model graph database for PostgreSQL. AgensGraph offers the graph analysis environment for highly connected data in which users can write, edit, and execute SQL and Cypher query together at the same time. AgensGraph comes along with PostgreSQL compatibility and PostgreSQL Extensions.
On the same vein: Redfield has integrated OrientDB with Knime Analytics Platform, a tool for advanced analytics and machine learning. We expect to see more graph database integrations.

Bringing #graphdatabases technology and advanced analytics together
We at Redfield are proud to announce a new integration between #OrientDB graph database and #KNIME Analytics Platform, a tool for advanced analytics #AI /#machinelearning/ #deeplearning
Ontology and Data Science usually don’t go in the same sentence. Favio Vázquez from Ciencia y Datos argues they should.

Ontology and Data Science
How the study of what there is can help us be better data scientists.
How are you going to visualize your Ontology? James Malone from SciBite explores the options.

Exploring ontology visualisation techniques for biological data
What’s the most useful way to visualise an ontology? SciBite CTO James Malone gives his views on answering this commonly asked question regarding ontology visualisation techniques.
Graphs and Deep Learning go together well. David Mack from Octavian shows how to get started.

How to get started with machine learning on graphs
Since our talk at Connected Data London, I’ve spoken to a lot of research teams who have graph data and want to perform machine learning on it, but are not sure where to start. In this article, I’ll share resources and approaches to get started with machine learning on graphs.
Related posts:
 Graph explosion and consolidation. The Year of the Graph Newsletter Vol. 14, June 2019
Graph explosion and consolidation. The Year of the Graph Newsletter Vol. 14, June 2019
 The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
 Graph-based data science, machine learning and AI. The Year of the Graph Newsletter Vol. 23, Spring 2021
Graph-based data science, machine learning and AI. The Year of the Graph Newsletter Vol. 23, Spring 2021
 Graph Therapy. The Year of the Graph Newsletter Vol. 20, June / May 2020
Graph Therapy. The Year of the Graph Newsletter Vol. 20, June / May 2020

