Graph gets funding. The Year of the Graph Newsletter Vol. 7, November 2018

October 2018 was the busiest month in the busiest year in graph history, hence the longest Year of the Graph newsletter to date. Neo4j lands a massive funding round, Tinkerpop is moving forward, the most important knowledge graph research event with key industry presence, W3C organizing a Workshop on Web Standardization for Graph Data, and new knowledge graphs and tools are out.
Neo4j just announced a new funding round of 80 million, almost as much as it had raised in the last 10 years combined. What this means in a nutshell: VC validates the view that graph databases are going mainstream. Neo4j gets an even longer runway and the chance to widen its lead in the market. We will see further funding for the competition as well, probably sooner than later.
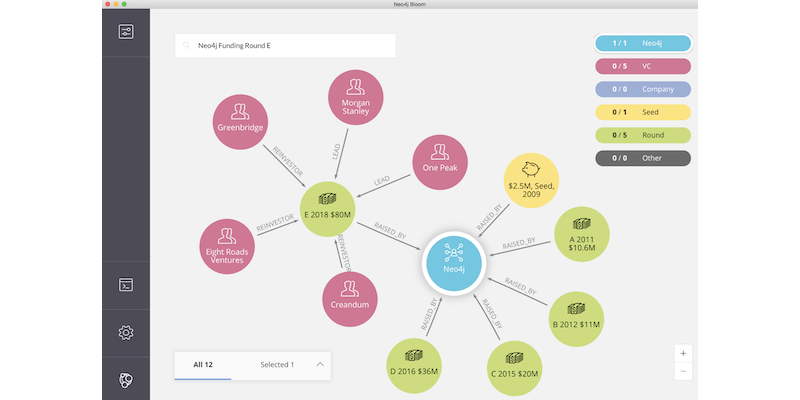
We Just Closed the Largest Single Investment in the Graph Space. Now What?
I’m thrilled to announce that Neo4j has just closed $80 million in a series E funding round.
After his sabbatical, Marko Rodriguez, Apache Tinkerpop’s mastermind, returns with a paper outlining Tinkerpop’s future. TinkerPop4 will be along the lines of the vision outlined last year, and will start development in the Spring 2019. An interesting read whether you are getting started with Tinkerpop or have been using it for years.
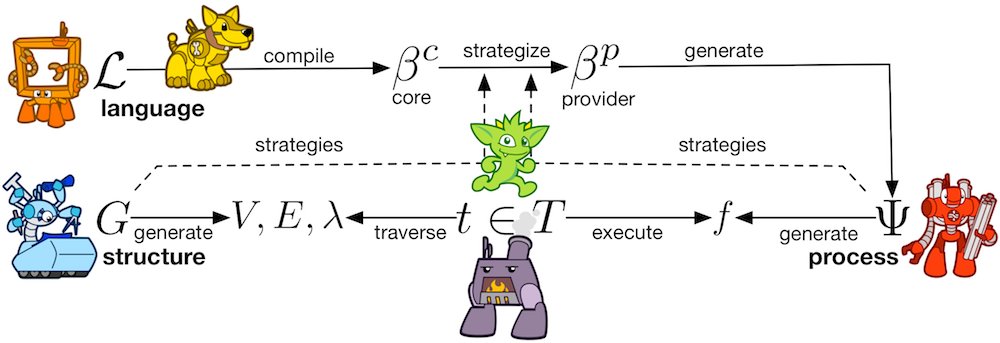
The Graph Traversal Machine: Close Encounters of the Fourth Kind
This article discusses the path forward on Apache TinkerPop’s next and final version: TinkerPop4
If you are into more down-to-earth Tinkerpop knowledge, Microsoft’s Jayanta Mondal explains that the way Gremlin queries are written has an impact on their performance. Gremlin is not like most query languages you are used to working with probably, and these tips apply not just to Azure Cosmos DB, but beyond as well.
Analyzing and improving the performance of Azure Cosmos DB Gremlin queries
The goal is to explain the basic constructs and the execution model of gremlin queries, and how understanding those basics can empower one to debug, analyze, and improve Gremlin queries against Azure Cosmos DB.
More Gremlin query tips from Microsoft’s Jayanta Mondal, this time on how to use pagination.
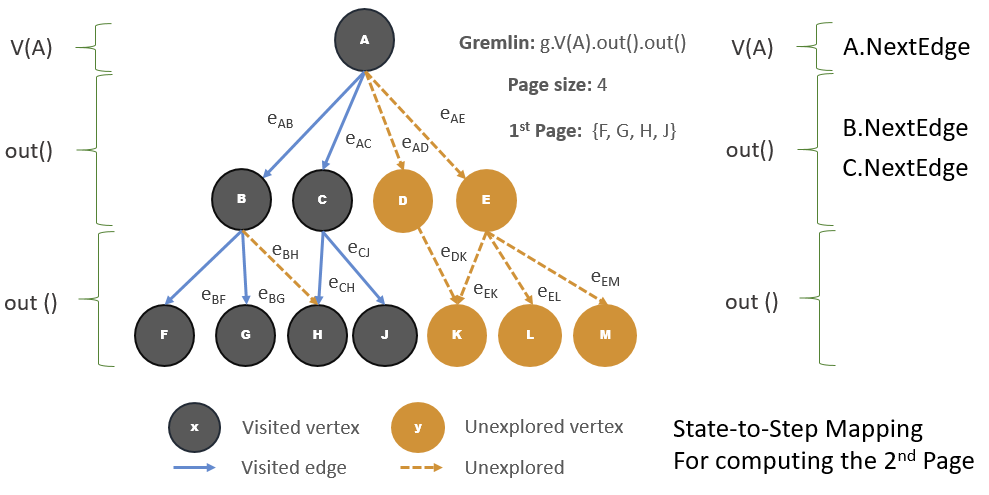
The curious case of pagination for Gremlin queries
Why is pagination a hard problem for TinkerPop graph databases? What can we do as application developers? What else can we achieve as a by-product?
More query language news: if you’ve been following this topic, you must know about the Neo4j-lead initiative for a common query language for property graphs. Now the W3C has embraced this initiative, and has announced a workshop to be held on the topic in Berlin this March.

W3C Workshop on Web Standardization for Graph Data
Creating Bridges: RDF, Property Graph and SQL
ISWC is the most important semantic web conference. This year an incredible wealth of research was presented, but perhaps the highlight was the presence of industry giants such as Google, Microsoft, eBay and LinkedIn who elaborated on how they are using knowledge graphs at scale in the real world, without necessarily using Semantic Web technology. Juan Sequeda from Capsenta summarizes.
International Semantic Web Conference (ISWC) 2018 Trip Report
ISWC has been my go-to conference every year. This time it was very special for two reasons.
One of the things that attracted attention in ISWC, and beyond, was TBL’s initiative called Solid, which utilizes Semantic Web technology under the hood. Ruben Verborgh is one of the people who are working on this, and here he presents the vision and motivation behind Solid.

Decentralizing the Semantic Web through incentivized collaboration
Decentralizing personal data storage allows people to take back control of their data, and Semantic Web technologies can facilitate data integration at runtime.
One of the topics that permeated ISWC was using machine learning to enhance knowledge graphs. But perhaps this also works the other way round, according to researchers from DeepMind, Google Brain, MIT, and the University of Edinburgh. They propose the use of network “graphs” as a means to better generalize from one instance of a problem to another.

Google ponders the shortcomings of machine learning
Scientists of AI at Google’s Google Brain and DeepMind units acknowledge machine learning is falling short of human cognition and propose that using models of networks might be a way to find relations between things that allow computers to generalize more broadly about the world.
Google has announced new features for search – Activity Cards, Collections and Dynamic organization of Search results. To enable these, Search has to understand interests and how they progress over time.
To do this, Google has taken their existing Knowledge Graph and added a new layer, called the Topic Layer, engineered to deeply understand a topic space and how interests can develop over time as familiarity and expertise grow.
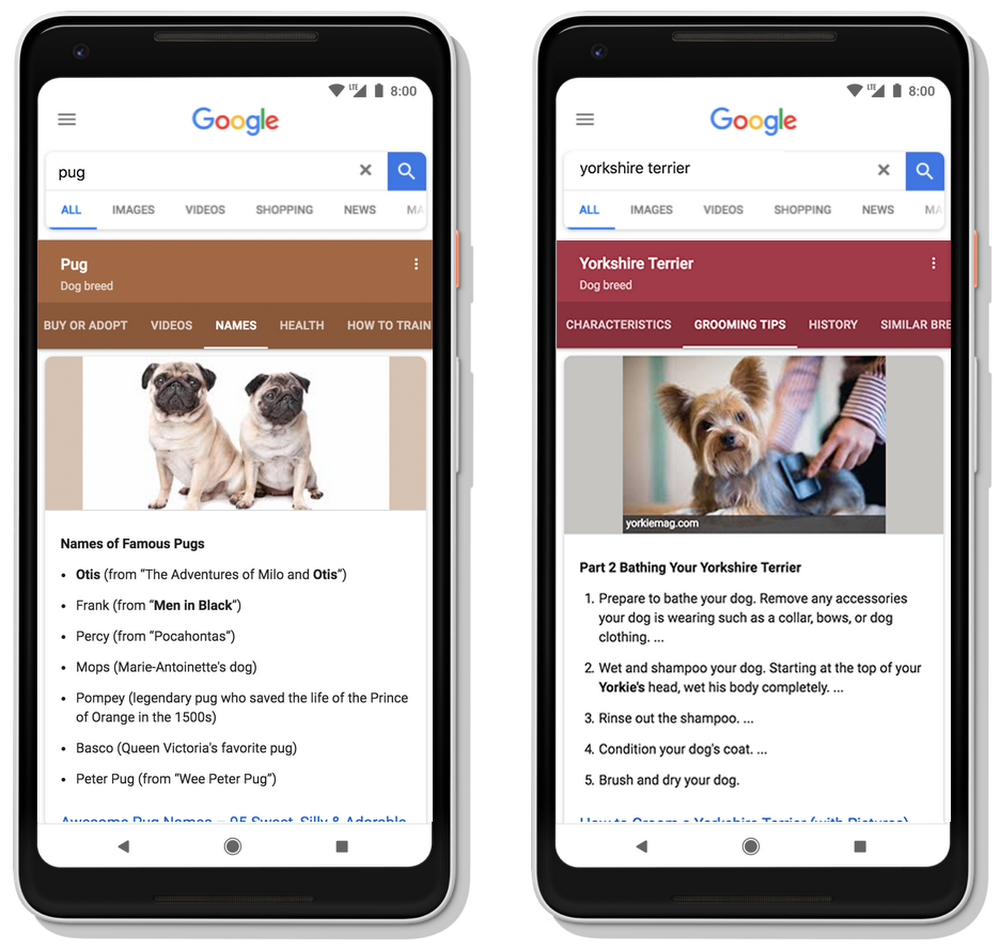
Helping you along your Search journeys
You ask what the capital of Costa Rica is, and we’ll tell you it’s San José. But in life we often take longer journeys, and people turn to Search for help in these moments too.
dataCommons is a Google-lead initiative for graph-shaped datasets which attempts to synthesize a single Knowledge Graph from publicly available data from open sources.
It links references to the same entities across different datasets to nodes on the graph, so that users can access data about a particular entity aggregated from different sources. It can be accessed via Python Notebooks, the dataCommons Knowledge Graph Browser, as well as APIs.

Welcome to Data Commons
Data Commons attempts to synthesize a single “Open Knowledge Graph” (OKG) from publicly available data from open sources
KBpedia is another comprehensive Knowledge Graph resource has just been made available to the public. Its upper ontology (KKO), full knowledge graph, mappings to major leading knowledge bases, and logical concept groupings according to 70 largely disjoint typologies have just been opensourced.
The KBpedia knowledge structure combines seven ‘core’ public knowledge bases — Wikipedia, Wikidata, schema.org, DBpedia, GeoNames, OpenCyc, and UMBEL — into an integrated whole.
KBpedia – Open-source Integrated Knowledge Structure
KBpedia is a comprehensive knowledge structure for promoting data interoperability and knowledge-based artificial intelligence
If you still are still unsure as to what a Knowledge Graph is, Spencer Norris has a go a this, concluding they are closely related to Ontologies, but the difference is not clear – size, maybe?

Where Ontologies End and Knowledge Graphs Begin
Recent attention from the research community has helped foment a significant debate among knowledge representation experts: what are knowledge graphs?
And what about the difference between Ontologies and Vocabularies? Holger Knublauch from TopQuadrant wonders, a few pundits have their say.

On ontologies
Most of the published “ontologies” barely go beyond RDF Schema and simply define classes, properties, domains and ranges, but no OWL whatsoever.
Back to knowledge graphs in the real world, here is one of the things Salesforce is using them for. What is an application network, and why does it need a graph? Phil Wainewright from Diginomica explains why MuleSoft, and Salesforce, are going graph. Hint: look out for more coming from Salesforce in the next few days.

Dreamforce 2018 – explaining MuleSoft’s application network graph
What is an application network? And why does it need a graph? MuleSoft’s founder and CTO help explain today’s announcement at Dreamforce 2018
A new tool for working with Knowledge Graphs is out – Gra.fo from Capsenta. Gra.fo claims to be the only visual, collaborative, and real-time ontology and knowledge graph schema editor in existence. Many interesting features, perhaps the most surprising one: support for property graphs.
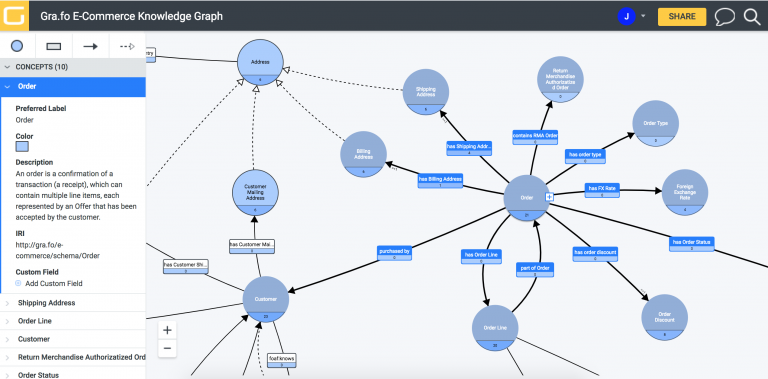
Gra.fo, a visual, collaborative, real-time ontology and knowledge graph schema editor
A common frustration we’ve encountered is the lack of adequate tooling around ontology and knowledge graph schema design.
Neo4j works with property graphs, and not many people would think of it as their first choice for working with RDF. But if you are using Neo4j, and want to use RDF, there is a way – Jesus Barrasa’s Neosemantics plugin. Now there is a new version released, and Barrasa writes about some of the things you can do with it.

Creating a schema.org linked data endpoint on Neo4j
In this instalment of the QuickGraph series, I’ll show how to map a graph stored in Neo4j to an ontology (or schema, or vocabulary…) using the neosemantics extension.
RDF is probably not something you would think of in the context of Docker. But Maximiliano Osorio, Carlos Buil-Aranda and Hernán Vargas have analyzed more than 150.000 Docker images hosted in Docker Hub, creating more than 100 millions of RDF triples that include links to external resources such as the Debian Package Tracking System and The Docker Store, and published their dataset.

Welcome to DockerPedia
DockerPedia is an RDF linked dataset that stores the information about Docker images hosted in Docker Hub including 4.5 million of images, its layers and packages.
How about using RDF datasets for testing hypotheses in the domain of politics? This is exactly what some academics are doing, using Wikidata

How academics are using Wikidata to look for links between legislative behaviour and the biographies of Members of Congress
Earlier this year, we were fortunate enough to be contacted by Brian Keegan, Assistant Professor in Information Science at the University of Colorado Boulder, who specialises in the field of network analysis.
MarkLogic is usually not among the first names that come to mind when considering graph databases. MarkLogic’s value proposition is mainly built around working as an integration hub though, RDF is a very good match for this, and MarkLogic fully supports RDF and SPARQL. Now MarkLogic has just announced its data hub as a hosted service in the cloud.

Introducing MarkLogic® Data Hub Service
New MarkLogic Data Hub Service delivers both agile data integration and agile data infrastructure – with unmatched security and governance, and predictable costs.
GraphDB also has a new version out, 8.7. We take a look at key new features, introducing data wrangling and embeddings as the foundation for semantic search and machine learning, and discuss where these may lead to.
If you want to hear from leaders and innovators in Graph Databses, Knowledge Graphs, Linked Data and AI and Machine Learning, there’s just a couple of days left to join us in Connected Data London.

Semantics, meet Data Science: GraphDB adds support for data wrangling and similarity search
With the knowledge graph hype in the air, more people than ever are looking to find out how and why the Googles, Airbnbs and Ubers of the world are using knowledge graphs, and how such practices can be adopted elsewhere.
If you are interested in fragments of the process of selecting a graph database, Louis Chen discusses. Why fragments though? Because this is a very-very limited subset of the graph database options which is evaluated, and a limited set of criteria used as well. For the real deal, check out the Year of the Graph report.

An overview of Graph Database and Graph Visualisation in 2018
Recently, I have been working with my client who is Australian’s largest telecommunications to deliver a real-time data product. The product allows the client to visualize network performance/configuration overlaid on network and service topology.
To see the Year of the Graph research presented in November, you have 3 options: 1) Connected Data London, 2) Big Data Spain, and 3) Connected Data Berlin. The benefit of joining our Meetup in Berlin? It’s free, and you also get to see local heroes ArangoDB in action – check it out! Spots are limited, so get yours now to avoid disappointment.
The Year of the Graph in Berlin
What can you get for free in Berlin, that you would have to get out of your way to get in, say, London or Madrid? A few things, including the most up to date and comprehensive research on graph databases, plus the local heroes of this scene.
Related posts:
 A gravitational wave moment for graph. The Year of the Graph Newsletter Vol. 11, March 2019
A gravitational wave moment for graph. The Year of the Graph Newsletter Vol. 11, March 2019
 Knowledge graphs in Gartner’s hype cycle. The Year of the Graph Newsletter Vol. 5, September 2018
Knowledge graphs in Gartner’s hype cycle. The Year of the Graph Newsletter Vol. 5, September 2018
 Graphs in the cloud. The Year of the Graph Newsletter Vol. 12, April 2019
Graphs in the cloud. The Year of the Graph Newsletter Vol. 12, April 2019
 The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025

