Graph Database market update, September 2024: Google Cloud Spanner Graph, Amazon Neptune, Neo4j

Google enters the Graph Database market with Spanner Graph, AWS takes one more step towards the One Graph vision for Neptune, and Neo4j releases new self-service and GenAI features.
There is no news in August. While you should not take this Umberto Eco quote 100% to heart, the truth is that major news are rarely announced in August. PR people are people too, and who likes to work in the month on which traditionally most people take their much needed time off – which also means going offline?
Product news are no different, and making product announcements in August seems like an odd choice. Nevertheless, this is what both AWS and Google just did in August 2024. Both announcements have to do with their Graph Database offerings, moving them forward in significant ways. Neo4j on the other hand waited until September 4. Here is a breakdown of the news and its impact on the market.
The Big 3 cloud providers – AWS, Microsoft Azure and Google Cloud – collectively make up for the vast majority of the cloud market. Even with if the rumored return to on-premises is going to materialize, the Big 3 still exert a huge influence over technology directions and budgets. When one of the Big 3 enters a new market, that immediately does a number of things.
First, it gives a boost to the market, as it provides validation and exposes it to a wider audience. Second, it forces everyone already in the market to take note and up their game, for fear of having their lunch eaten. Third, it creates co-opetition dynamics, as practically all vendors have to work with the Big 3 to make their products available to their clients.
We have seen this dynamics at play already in 2017 and 2018, when Microsoft and AWS made their Graph Database offerings available: Cosmos DB and Neptune, respectively. In August 2024, Google got into the Graph database action with Cloud Spanner Graph and AWS took another step towards graph data model integration. Neo4j on its part announced new capabilities for Aura, its cloud offering.
Why now, how to evaluate those offerings, and what does that all mean for the Graph Database market? These are the questions this brief analysis is meant to address.
Google Cloud Spanner goes Graph
Google Cloud Spanner is a globally distributed operational database that’s been generally available since 2017. The in-house version of Spanner was originally built by Google to handle workloads like AdWords and Google Play, that were, according to Google, previously running on massive, manually sharded MySQL implementations.
As Andrew Brust explains in his 2017 introduction of Spanner for ZDNet, Google needed a database that had native, flexible sharding capabilities, adhered to relational schema and storage, was ACID-compliant and supported zero downtime. Since such a database didn’t exist, Google created its own, and thus Spanner was born. After battle-testing the product in-house, Google made Cloud Spanner generally available.
In August 2024, Google introduced what it dubbed Spanner Graph, adding graph capabilities to Spanner. Spanner now supports the newly introduced ISO Graph Query Language (GQL). Spanner takes an idiosyncratic approach, effectively mixing the relational and graph model. It also has built-in search capabilities, and offers scalability, availability, and consistency as well as integration with Vertex AI for AI-powered insights.
For the most part, these features leverage Google’s ecosystem (Vertex AI and search) as well as the pre-existing capabilities of Spanner (scalability, availability, and consistency). But the core of the announcement really lies in the way graph features have been implemented on top of the existing SQL interface.
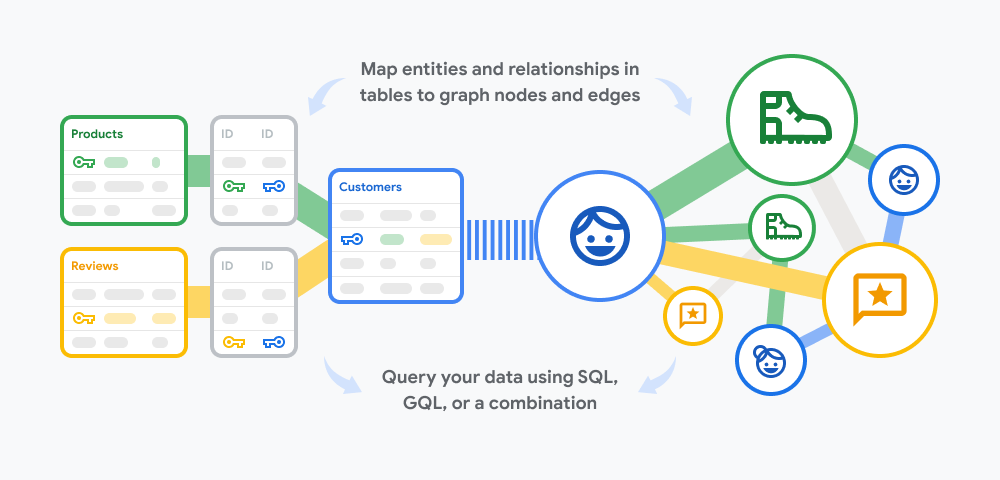
Google Cloud Spanner Graph lets users mix and match relational and graph data models
What this implies is that Spanner has not really implemented a new engine for graph. Instead, Spanner seems to have opted for adding a GQL interface on top of its existing SQL engine, as well as a way to designate which tables correspond to nodes and edges in the graph. Using the GQL interface, users are able to execute graph queries on Spanner, and mix them with SQL queries as well.
Is that a good thing? And how well that will it work in practice? Spanner Graph seems like an implicit nod to Stonebraker and Pavlo, who argue something along the lines of “SQL is all you need”. It’s certainly possible to create a graph database interface on top of a relational database, and others have done it previously too – Microsoft SQL Server Graph and Oracle Graph come to mind.
However, working with graphs is not as simple as adding a few tables to model graphs using a relational engine. First, because using SQL to express graph queries would result in extremely complicated queries that are a nightmare to create and maintain. And second, because running these queries on the underlying relational engine can lead to a huge amount of joins, having a dramatic effect on performance.
How does Spanner Graph work?
Spanner has addressed the first point by implementing GQL. That enables users to express queries in a bona fide graph query language, making Google one of the first vendors to offer support for the newly minted GQL standard. The fact that GQL and SQL can be mixed and matched when writing queries is an interesting feature. If nothing else, it hints at how Spanner works under the hood.
To address the second point, however, GQL itself is not enough. Simply translating GQL to SQL and running it over relational tables could lead to problematic performance for Spanner Graph. At this point, we don’t really know whether Spanner Graph uses graph-specific optimizations. What we do know is that Spanner claims to offer single-digit ms latency for SQL queries, and that Spanner’s distributed nature calls for attention when executing those SQL queries.
We don’t currently have any 3rd party references regarding Spanner Graph’s performance. Except for a quote provided by the Credit Karma Engineering team, we don’t know how Spanner Graph is used in production either. We hope that more material will be made available to clarify those points, crucial to inform purchase decisions in the Graph Database market.
In any case Spanner Graph makes for an interesting offering for existing Spanner users, which presumably is Google’s initial primary target audience. Google lists a number of use cases for Spanner Graph: Product recommendations, Financial fraud detection, Social networks, Gaming, Network security, and Graph RAG.
All of the above are indeed prime examples of use cases for Graph Databases. And it’s been that way for a long time – with the obvious exception of Graph RAG. Graph RAG may well be what tipped the balance to make Google decide to address the Graph Database gap in its portfolio by adding graph features to Spanner. Presumably, Google wants a piece of the GenAI action, and checking the Graph RAG box could help.
Querying RDF knowledge graphs with openCypher on Amazon Neptune
It may seem like Google decided to come out and play Graph out of the blue. But as reported by YotG reader Seb Heymann, Bei Li, Spanner Graph cofounder, has contributed to the GQL ISO group for the last 5 years. That’s long before GenAI and Graph RAG were a thing.
AWS, by contrast, has been a force to be reckoned with in the Graph Database market since Neptune’s debut in 2018. Its latest announcement is that Neptune users can now build and deploy knowledge graphs with RDF and openCypher.
As Neptune’s team shares, when users build an application that uses a Graph Database, they’re typically faced with a technology choice at the start: There are two different types of graphs, Resource Description Framework (RDF) graphs and labeled property graphs (LPGs), and their choice of which to use will determine which query languages they can use.
RDF graphs use SPARQL as their query language, and for LPGs the query languages are Gremlin and openCypher. Users and developers who are new to graph technology are often confused about having to make this choice, which Neptune’s team calls “a rift in the entire graph industry”. Reasons for this division are manifold: technology limitations, lack of awareness, and strongly held views.
RDF, with its standardized serialization formats, global identifiers, and the availability of Linked Open Data sets, is of particular value for data architects who seek to build, integrate, and interchange graph data. Application development teams often prefer LPG query languages such as openCypher, due to their intuitive syntax, ecosystem maturity, and features such as built-in support for path extraction and algorithms.

Amazon Neptune lets users use RDF knowledge graphs with the openCypher query language
Neptune’s team has been working for a long time towards what they call the One Graph vision, so this move is by no means a surprise. It’s the next logical step towards the implementation of that vision. Neptune has a lot to gain by this, as the end game may even be unifying the two engines they currently operate for Neptune under the hood – one for RDF and one for LPG data.
For Neptune, that would mean having a much cleaner and simpler implementation with less overhead and more efficiency. For users, being graph data model agnostic should make life simpler and easier and offer more choice.
One caveat, however, is that mixing and matching data models and query languages may not be entirely straightforward as an interim state, especially for beginners. Either way, we expect to see Neptune continuing the work towards the realization of the One Graph vision, with the next stop probably being support for GQL.
Neo4j gets Aura GenAI, self-service, performance and security features
In contrast with Google and AWS, Neo4j focuses all its energy on one thing only – its eponymous Graph Database product. This, in fact, is what its CEO Emil Eifrem has long ago called out as Neo4j’s competitive advantage against the Googles and AWSs of the world.
Like AWS, Neo4j is also walking a consistent path in terms of its product roadmap. Sudhir Hasbe, the CPO Neo4j appointed in 2023, set the tone immediately. Neo4j has gone all in on GenAI and Large Language Models, with integrations and related features having been released ever since.
GenAI may be a relatively new priority for Neo4j, but Aura, Neo4j’s fully managed cloud, is a long-standing one. Not only have GenAI features been deployed with a priority on Aura, but now it’s Aura’s turn to be given a GenAI lift. Neo4j just announced an array of new features as well.
Aura gets a new console with GenAI co-pilot as a unifying hub to easily administer, manage, ingest, model, and visualize data efficiently across all of Neo4j’s offerings and tools. There is also a new self-serve offering, Neo4j AuraDB Business Critical, at a 20%+ lower price point than Neo4j’s traditional AuraDB Enterprise offering and designed for highly available workloads requiring advanced security.
Another new feature is the new no/low-code interactive dashboard builder NeoDash that lets users create maps, graphs, bar and line charts, tables, and other visuals for anyone to understand, analyze, and interact. While developers have used NeoDash as part of Neo4j Labs, it is now a fully supported offering for enterprises.
Last but not least, there are performance and security features announced. 15x scale improvement in real-time read capacity, and advanced enterprise control, audit, and compliance capabilities that include Customer Managed Encryption Keys and Security Log Forwarding.
The Graph Database market is moving forward
Compared to the announcements from Google and AWS, it would be fair to say that Neo4j’s features seems like incremental improvements. In all fairness, however, Neo4j has been consistent in releasing such features. This signifies the constant evolution of Neo4j’s offering.
Overall, the news paints an interesting picture. Google seems to be operating in typical Big 3 fashion, ever-expanding its offering. AWS has a dedicated product team for its Neptune database, and the same obviously holds for pure-play Graph Database vendors, with Neo4j exemplifying this.
The one vendor that’s practically missing from this picture is Microsoft. In theory, Microsoft offers Graph Database capabilities for Cosmos DB, an offering similar in some ways to Spanner, as well as SQL Server, its relational database timeless hit. In practice, however, both seem stagnant and not actively developed graph-wise.
It would be interesting to see whether Microsoft, whose work on Graph RAG greatly benefits Graph Database vendors, decides to actively pursue this market too. Either way, the market is moving forward, and we’ll be keeping an eye out to evaluate how these news move the needle.
Related posts:
 The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
 Graphs, analytics, and Generative AI. The Year of the Graph Newsletter Vol. 25, Winter 2023 – 2024
Graphs, analytics, and Generative AI. The Year of the Graph Newsletter Vol. 25, Winter 2023 – 2024
 Return of the Graph: Geospatial Knowledge Graphs, Personal Knowledge Graphs, and Evolution. The Year of the Graph Newsletter Vol. 24, Spring 2023
Return of the Graph: Geospatial Knowledge Graphs, Personal Knowledge Graphs, and Evolution. The Year of the Graph Newsletter Vol. 24, Spring 2023
 A gravitational wave moment for graph. The Year of the Graph Newsletter Vol. 11, March 2019
A gravitational wave moment for graph. The Year of the Graph Newsletter Vol. 11, March 2019


6 comments to “Graph Database market update, September 2024: Google Cloud Spanner Graph, Amazon Neptune, Neo4j”
Bei Li, Spanner Graph cofounder, has contributed to the GQL ISO group during the last 5 years, long before GenAI and GraphRAG being a thing.
To nuance “It may seem like Google decided to come out and play Graph out of the blue.”
Thanks for sharing. Adding to the text, and crediting you for the tip.
Check out RelationalAI’s offering for comparison. Relational Knowledge Graph inside Snowflake’s Snowpark Container Services. The Knowledge Graph Coprocessor…. relational.ai
I entered my name and email address and got this
Message *Subscribe to the Year of the Graph Newsletter
Keeping track of all things Graph Year over Year
Unable to process request. Please, contact support.
Thanks for reporting – HTML snafu, fixed now. Added you to the list manually.
[…] Graph database vendors keep evolving as well. Google entered the graph database market with Spanner Graph, AWS took one more step towards the One Graph vision for Neptune, and Neo4j released new self-service and GenAI features. Spanner Graph is now GA, Neo4j has introduced Aura Graph Analytics, and Amazon Neptune powers Amazon Bedrock Knowledge Bases with Graph RAG. […]