Layers of Meaning: Context Graphs, Graph Memory, and Ontologies for AI. The Year of the Graph Newsletter Vol. 31, Summer 2026

What does it take to build an AI system that actually knows what it means? Not what it says. Not what it retrieves. What it means.
Everyone is building context layers and ontologies for AI now. Context graphs are AI’s next trillion-dollar opportunity, we are told, and ontology is the secret sauce. The term shows up in product launches from Atlassian, AWS, Databricks, Google, Microsoft, Neo4j, and Snowflake.
There’s just one problem: not everyone means the same thing when they talk about context layers or ontologies. Slightly ironic, considering context layers and ontologies are meant to address, well, meaning.
What’s underneath this wave is something the graph and semantics community will recognize: a mass convergence on problems that have been worked on for decades, now arriving at scale, under new branding.
Forrester traced the context graph lineage 40 years back to Enterprise Architecture. Deborah McGuinness wrote “Ontologies Come of Age” in 2003. The Semantic Web market reached $2.71 billion and is growing at 23% CAGR. This is not new territory. What is new is the scale, and the urgency.
Scale changes the calculus. When every major data platform ships an “ontology” feature, the word migrates. When every startup promises a context layer, the concept stretches. When every agent framework claims graph memory, the question becomes: whose meaning survives the handoff between systems? Who owns the ontology? More fundamentally – what do we talk about, when we talk about ontology?
In this issue of the Year of the Graph, we follow three converging threads: the architecture of the context layer, the mainstreaming and quiet dilution of ontology, and the emergence of graph memory as enterprise infrastructure. They converge on a single point: graph structure is necessary, but not sufficient. What matters is who gets to decide what the data means, and whether meaning can move along the data.
📋 Table of Contents
- The AI Context Layer: Three Types of Context, Three Different Problems
- Context, Graphs, and Semantic Layers
- Context Graphs are a Convergence, and Convergence Needs Architecture
- Ontologies for AI, by AI
- Everyone Has an Ontology Now
- Ontologies Come of Age (again)
- Ontology and Semantics Market, Education and Tools
- The LLM Wiki Pattern: From Personal Knowledge Graphs to Enterprise AI
- Knowledge Graphs, Memory and Context
- Graph Memory Structure
- Knowledge, Graphs, RAG, and Agentic AI
- Graph Databases Become Graph Engines
- Graph Data Is Table Stakes: Why Meaning Is the Real Differentiator
This issue of the Year of the Graph is brought to you by metaphacts, Graphwise, Modern Relay, yWorks, Graphlytic, Fluree, State of the Graph, and Connected Data London.



Why Enterprise AI fails in production

Enterprise AI agents frequently fail in production, often because of interactions with technical environments (like database schemas and APIs) that lack any semantics.
This whitepaper demonstrates why organizations need a ‘Semantic Control Plane’—an architectural layer built on open standards that formally defines and binds business concepts to technical execution before an AI agent takes action, to ensure reliable and accurate agent outputs.
The AI Context Layer: Three Types of Context, Three Different Problems
Everyone needs a context layer, but what exactly is it and how do you get one?
Many organizations are looking for advice on private context. They all start the same way: “how do we make our context usable for agents?” The phrasing is always the same. What’s underneath it never is. The moment you look closely, it breaks apart into different problems that only look alike from a distance.
What sorts this space, per Elisenda Bou-Balust & Miguel Arias is the kind of context you’re dealing with. That decides what exists to work with & which tools are on the table. Their AI Context Layer Market Map lays out this space in 3 buckets.
Bucket 1 is context internal to agents. The agent’s own memory and operating manual. Bucket 2 is institutional knowledge. The scattered docs, chats and tickets your company already lives in. Bucket 3 is systems of record. The hard operational data, split by who (or what) generates it: human-generated business records and machine-generated telemetry.
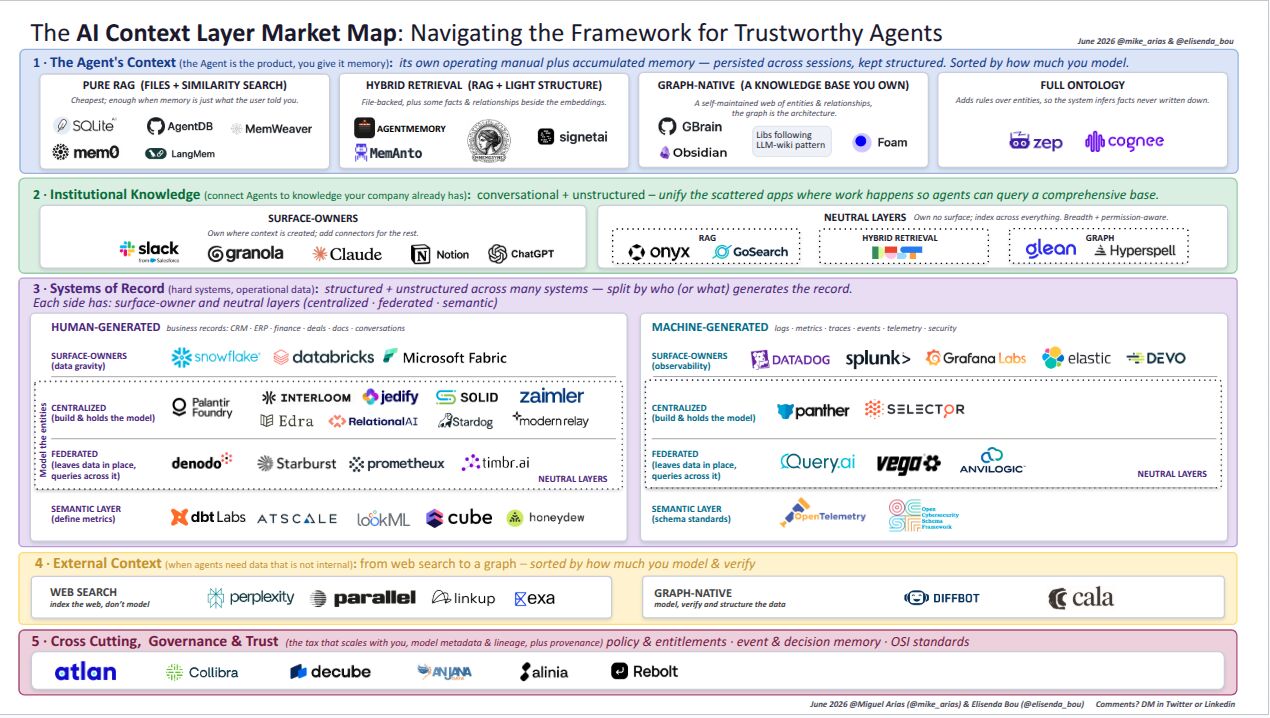
The AI Context Layer Market Map. Source: Elisenda Bou-Balust & Miguel Arias
Each bucket has its surface-owners (who own where work happens) vs. neutral layers (who index across everything): centralized, federated, semantic. Plus two things that cut across: governance & trust (the tax that scales with you), and the emerging public data context layer (verified world facts and data , so agents can query external knowledge).
An AI agent operating inside a real business needs three kinds of context, and they map directly onto what the context layer has to encode: Knowledge – the map of the business, Expertise – how work actually gets done, and Norms – the rules of acceptable action. This is what Prukalpa argues in “What an Enterprise Context Layer Actually Is“.
Context graphs are structured, persistent records of product data, customer data, ontologies, and decision traces Dan McCreary argues. They capture what happened, why it happened, who approved it, and which precedents justified it. McCreary’s textbook defines context graphs as a discipline sitting between three mature fields: knowledge graphs, retrieval-augmented generation (RAG), and process mining.
Enterprise AI Is Only as Good as the Foundation It Runs On

Most deployments don’t fail because of the model. They fail because the data underneath it is disconnected.
Enterprises poured millions into models that still return wrong answers. Still hallucinating. Still can’t explain their outputs. The investment wasn’t wasted but the foundation was just missing.
GraphRAG fixes that. Graphwise Platform made it possible. It’s production-ready with out-of-the-box workflow templates, built-in guardrails, and a governance layer that profiles and monitors every query in real time. The teams that moved early aren’t looking back.
Context, Graphs, and Semantic Layers
In “Understanding Context“, Bill Inmon and Jessica Talisman argue that context is a human-led social agreement that must be maintained. Humans decide what counts as context and what constitutes knowledge. The work is sociotechnical by nature – the deliberate alignment of human knowledge practices with the systems built to extend them.
Context is to AI what data was to BI, Prukalpa argues: the raw input that allows the system to function. She draws a parallel between semantic layers that came before, and context graphs that everyone is looking to get now. The parallel points out failure modes for semantic layers: misaligned incentives, migration math and the execution path.
Context graphs are framed as a trillion-dollar market. So the trillion-dollar question is – will this time be different? Foundation Capital’s thesis argued that vertical agents will own context because they “sit in the execution path”. The sales agent will capture renewals context, the support agent will capture escalations context, and so on.
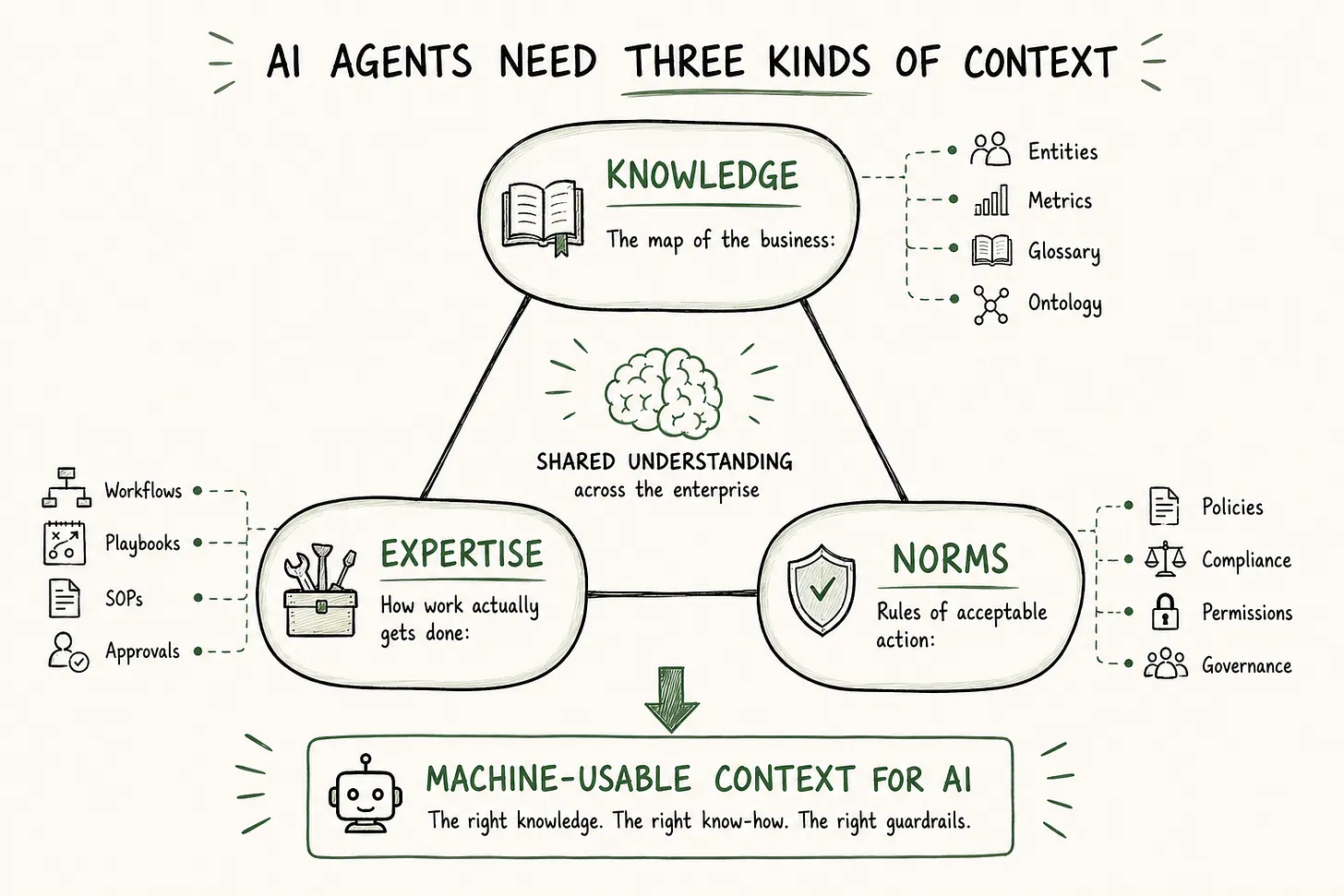
AI agents need three kinds of context: Knowledge, Expertise, and Norms. Source: Prukalpa
This quietly assumes there’s a single execution path where context naturally accumulates. Prukalpa argues that’s true for simple workflows, but not beyond that. Most decisions happen across workflows and systems, and context comes from everywhere.
Heterogeneity is moving up the stack today, from a mess of data tools to an ever growing mess of AI agents, copilots, and applications. This means that while execution paths may be local, context is global. If context graphs are going to live up to their promise, we’ll have to learn from what worked and did not work previously.
Prukalpa offers four principles to make the context layer a reality beyond the hype: 1. Built for human collaboration, not just machines. 2. Machine-native and built for change. 3. Open, portable, and bigger than any single vendor. 4. One shared brain, many agents.
Lakehouse graph database for context assembly & multi-agent coordination
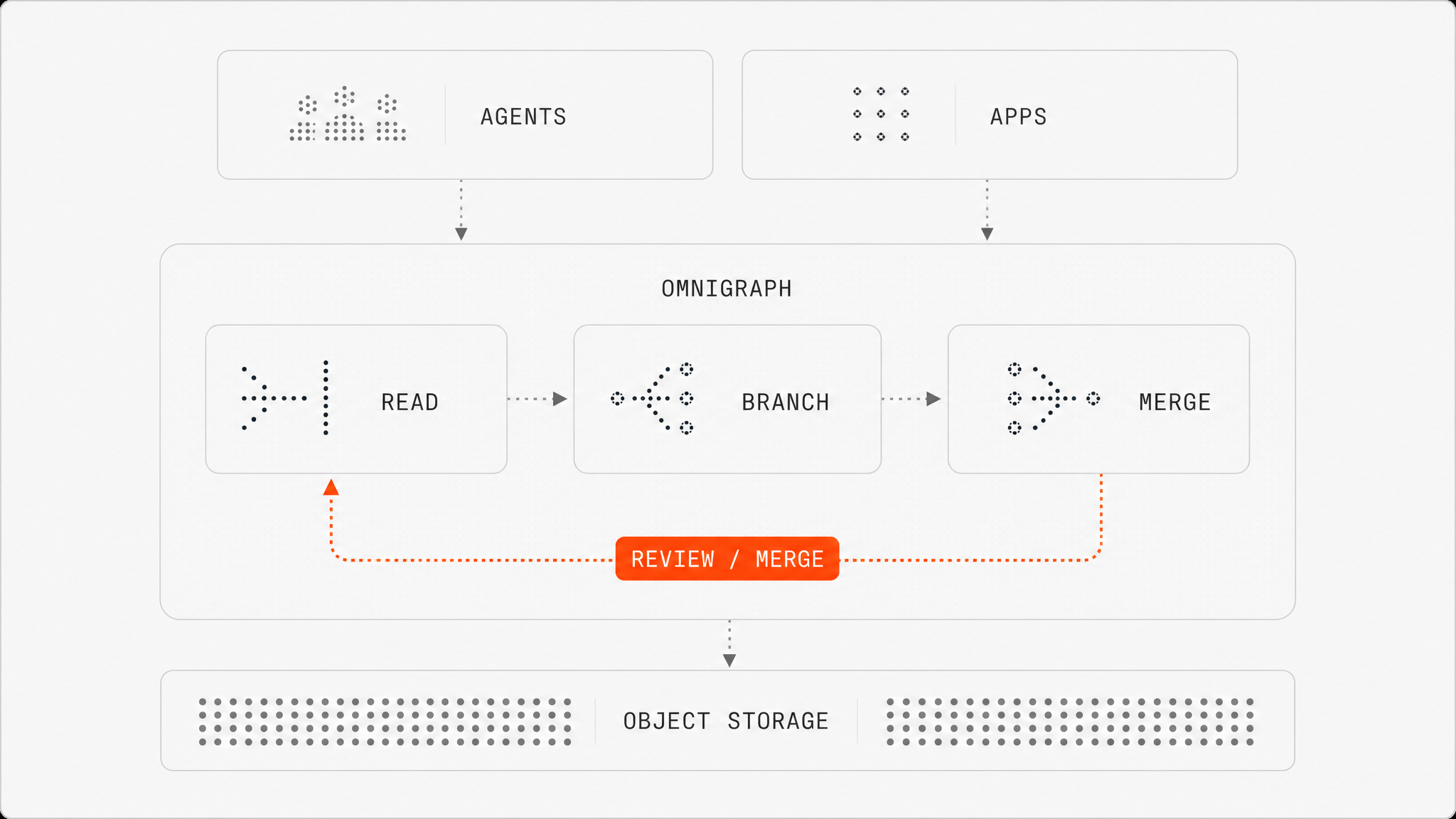
Most graphs stop at storage. As agent fleets grow, they don’t just read your graph, they write to it at machine speed. Without structure, those writes collide: conflicting updates, silent errors and knowledge decaying as fast as it’s created.
Omnigraph is the operational state and coordination layer for fleets of agents. Declare it as code, run it as a server, and let your agents traverse and enrich it on parallel isolated branches. Every change is reviewed and merged safely, so knowledge actually compounds.
Context Graphs are a Convergence, and Convergence Needs Architecture
When Foundation Capital declared context graphs AI’s next trillion-dollar opportunity in late 2025, it looked like a new category arriving – and with it, a new set of questions about context graph architecture. What it was is something older arriving under a new name: the problem of structuring organisational knowledge to make it discoverable and usable.
Forrester’s Charles Betz made this point in “Context Graphs Are A Convergence, Not An Invention.” He traced the entity graph lineage back 40 years through Enterprise Architecture (EA), the discipline responsible for mapping an organisation’s technology, capabilities and their relationships.
Configuration Management Databases, Application Performance Monitoring and process mining are established disciplines with their own tooling. These disciplines have been building the pieces of a unified context graph in isolation for decades. The decision trace layer – who approved what, why, under what authority – isn’t missing. It’s fragmented: scattered across Slack threads, incident postmortems, Jira tickets, and people’s heads.

Context graph architecture in 2026. Image: Daniel D. Mendoza
What that fragmentation represents is something Jessica Talisman named directly in “Ontologies, Context Graphs, and Semantic Layers“: this is fundamentally a knowledge management problem. Eliciting tacit knowledge, encoding reasoning, and representing it in formal, machine-queryable form requires systematic knowledge engineering.
Another conversation runs in parallel, largely unaware of decision traces and knowledge engineering. The BI world has its own semantic layer: the abstraction above the data warehouse that maps business terms to query logic, seen today in tools like dbt and AtScale’s semantic layers, or Cube’s universal semantic layer.
These three threads – the context graph thesis, Betz’s EA-grounded convergence, and the knowledge graph and semantic technology tradition – are moving toward each other. The knowledge architecture problem is what connects them.
In “Why Context Graphs Need Knowledge Architecture“, George Anadiotis maps that connection, and points to where the work is already being done. The follow-up, Context graph architecture in 2026, explores this in engineering terms. Context graphs are a convergence, and convergence needs architecture argues Kurt Cagle.
Go Beyond Code Co-Pilots for Network Visualization Apps

Network visualizations transform complex data into actionable insights—but they demand more than generic AI. They require precise layouts, interactive performance, and architectural rigor that LLMs alone can’t deliver.
See how specialized tools + AI co-pilots solve this. Join the yWorks webinar for practical techniques on AI-assisted network visualization development. Real examples: From raw prompts to production-ready apps.
Ontologies for AI, by AI
As more vendors and people start moving towards the realm of data modeling, knowledge engineering and semantics, inevitably the water gets muddied. In the last few months, we’ve seen the “ontology” and “context” being used by vendors such as Atlassian, AWS, Databricks, Microsoft, Neo4j and Snowflake.
Databricks was the latest to announce ontology at the center of its biggest summit launch. There were precursors to this, both conceptual – the Data Lakehouse 2.0 concept – and technical – the OntoBricks Digital Twin Builder. Google also introduced its Knowledge Catalog – “a unified, dynamic context graph of your entire business enabling you to ground agents in all of your business data and semantics”.
Databricks CEO Ali Ghodsi called Databricks Genie Ontology the secret sauce – a live graph of everything an organisation knows. Frédéric Verhelst points out there are questions worth asking not just about Databricks, but about any such offering. Not what it does, but whether you own it.
Can you move the meaning to another platform, or does it live inside theirs? Can the system prove an action is allowed before an agent takes it, or only log what it did after? Did you author the meaning, or does the platform learn and hold it? On all three, Verhelst concludes, Genie Ontology is a learned context layer inside Databricks, open in the table-format sense, not the meaning sense.

Databricks calls it an ontology. Do you own it? Source: Frédéric Verhelst
What these offerings bring to the table is not aligned with what ontology practitioners mean when they refer to ontologies. This is where opinions and attitudes diverge. Perhaps more important however – uses cases also diverge.
As Andrea Volpini wrote in “Ontologies for the Agentic Web“, ontologies were created to make human knowledge understandable to machines. In the agentic era, their role expands: they are no longer only formal artifacts for interoperability, but runtime structures that help AI agents retrieve, validate, remember, plan, and act without losing meaning.
That is powerful but also risky. “The Ontology trap“, Sergey Vasiliev notes, is that AI can generate structure faster than organisations can validate meaning. “Pitfalls in AI-Generated Ontologies” discusses how to move from enthusiasm to reliability when using LLMs for ontology engineering, with two concrete contributions: the Ontology Toolkit and the Ontology Pitfalls Detector.
Stop Querying. Start Discovering.
Your knowledge graph holds answers your queries never reach. Graphlytic Cloud puts AI-aided exploration in the hands of knowledge analysts. Search for graph patterns, trace hidden connections, and surface insights across your data without writing a single query.
– Natural language AI commands – no queries required.
– Intuitive, fast graph exploration and discovery.
– Built for enterprise knowledge graphs. Works with all major graph DBs.
– Zero infrastructure setup, collaborative by default.
👉 Start your 7-day free trial now!
Everyone Has an Ontology Now
Vasiliev notes the RDF assumption that meaning lives in ontology is breaking in the LLM era. Every language model has a map of your business concepts, Animesh Kumar chimes in. The real challenge isn’t constructing an ontology, but deciding where your enterprise’s meaning diverges from the one the model already has, and correcting only that.
AI did not replace the need for ontology. It brought new ways to create and use ontologies, and made the cost of not having one visible – in bad decisions, audit failures, and automation that cannot be trusted. The market has grown to the point where it now makes sense for Googles of the world to directly address it.
Ontologies are moving from the background into the operating layer of AI systems. They are no longer just reference models for search, data integration or semantic publishing. In the agentic web, ontologies can shape how AI agents retrieve information, recognise entities, remember context, select tools, validate outputs and decide allowed actions.
Every AI agent failure, Sanjeev Mohan claims in his “FAQ on Metadata, Semantics, Taxonomy, Ontology, Knowledge Graphs, and Context“, can be traced back to the same root cause: nobody agreed on what the data means. Veronika Heimsbakk elaborates on the Living Knowledge Graph and who owns the meaning. A knowledge graph is a living information architecture, and the curation is the work, she argues.
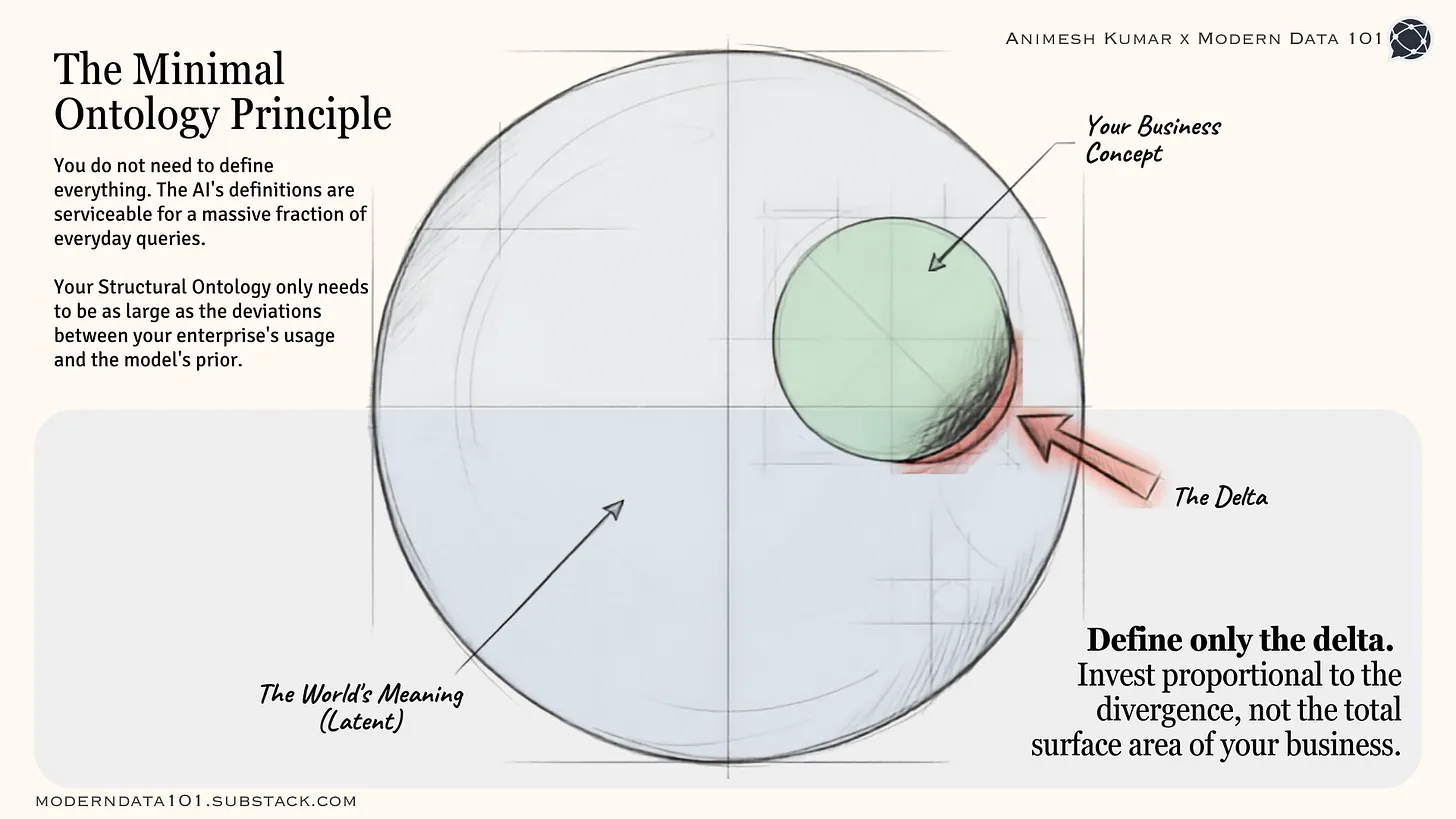
The Ontology Engineering Challenge is Not Building It, but Mirroring the Delta. Source: Animesh Kumar
“Everyone Has an Ontology Now“, Nicolas Figay points out. The word “ontology” has escaped its technical meaning and become a marketing asset. It signals rigor, structure, shared understanding. It implies the platform knows what your business means – not just what your data says. In the age of agentic AI, that is an enormously valuable claim.
The problem, Figay adds, is that most of what is being sold under that label is something else: a governed property graph. A business glossary with relationship types. A typed schema with some constraints layered on top. These are not worthless – they are genuinely useful artifacts.
But they are not ontologies in any formal sense, and the distinction matters enormously the moment you ask an AI agent to reason on top of them. Plus, we would add, if you try using these artifacts in traditional ontology use cases. The distance between what vendors mean by ontology and how seasoned practitioners use ontologies grows alongside adoption.
Introducing FlureeDB

FlureeDB unifies data, provenance, governance, and AI memory in a single knowledge graph database, so every answer can be traced back to its source. Now #1 on the public SPARQLoscope benchmark, with native vector search and an MCP server for agents.
Ontologies Come of Age (again)
Seasoned practitioners respond to what’s going on in their own way. Some people qualify the use of the term “ontology”. Others call it out. Others yet see this as a pragmatic first step in the right direction. Convergence is happening, and it’s faster than what the community can process, adapt to, or agree on.
Neo4j included ontologies as a 1st class citizen in its roadmap. GraphAware CTO Christophe Willemsen compares Neo4j’s GRAPH TYPE with RDF/SHACL on architecture merits. Ultipa’s Jason Zhang attempts to bring ontology to LPG graph databases, combining OWL reasoning + SHACL rules over live data.
Gartner says lack of semantics causes inaccurate AI agents and wasted spending. Forrester points out why semantics, ontologies, and knowledge graphs matter for agentic AI. What we need to move forward is community and frameworks.
Ontologies have moved beyond the domains of library science, philosophy, and knowledge representation. They are now the concerns of marketing departments, CEOs, and mainstream business. This is what Deborah L Mcguinness wrote in “Ontologies Come of Age” back in 2003.
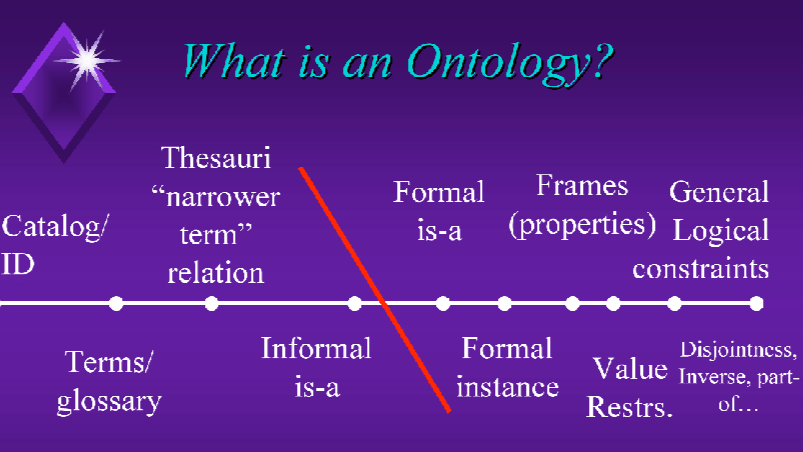
The ontology spectrum. Source: Deborah L Mcguinness
The ontology spectrum Mcguinness shared arose out of a conversation in preparation for an ontology panel at AAAI ’99. The panelists (Lehman, McGuinness, Ushold, and Welty), chosen because of their years of experience in ontologies, found that they encountered many forms of specifications that different people termed ontologies.
Frameworks such as Jessica Talisman’s Ontology Pipeline build on this, and can be valuable in establishing a common frame of reference and terminology. As she notes in her CDL24 talk “Intentional Arrangement“, controlled vocabularies, taxonomies, thesauri, ontologies and knowledge graphs have all emerged from the librarian’s toolbox.
Could it be that the Semantic Web never shipped, but its core idea just did, as Karim Ounnoughi puts it? Are there arguments that ontologists never finished and AI teams will have again, as Kurt Cagle claims? 25 years after its inception, the Semantic Web Market Research Report 2025-2030 by ResearchAndMarkets notes the market is set to expand from $2.71 billion in 2025 to $7.73 billion by 2030, at a CAGR of 23.3%.
Cagle compares RDF 1.2 vs. Neo4j/OpenCypher, and Talisman elaborates on choosing the right graph. Veronika Heimsbakk created a map of the RDF ecosystem, and Alcides Lopes suggests metagraphs to bridge the gap between data and meaning in Property Graphs.
Connected Data London 2026
10 Years Connecting Data, People and Ideas

Connected Data London 2026 is putting a spotlight on Context Graphs, capturing temporal lineage and decision traces behind autonomous behaviour.
If you are working on the architectures that give AI a “memory”, we want to see your work.
🔗 Guidelines & Submissions 🗓️ Deadline: 31 August
Ontology and Semantics Market, Education and Tools
Ontology and semantics are seeing growing adoption today, and estimates are they will underpin future functions too. Jessica Talisman provides an analysis of the Semantic and Knowledge Graph job market, exploring how demand for these roles is shaping.
Travis Thompson argues the agentic era is creating roles such as Context Engineer and Semantic Architect, while Jens Jorgenson gives an overview of product ontologies as they relate to the design process. The wave of educational content and tool releases on ontology is going strong.
Ashleigh Faith, Katariina Kari and Veronika Heimsbakk explore what is an Ontologist or Knowledge Engineer, and how do you become one. In the second part of the conversation, Faith is joined by ex-Amazon ontologists Beth Holmes and Christelle Maignan.
Kurt Cagle and Pallavi Karanth share common beginner mistakes in ontology. Karanth also weighs in on one of the most under-discussed skills in ontology engineering: trimming.
Simrat Saini explores how to make tacit knowledge accessible for the enterprise, and Stuart Winter-Tear stresses that tacit knowledge is not simply undocumented information waiting to be formalized. The ontology problem, Kurt Cagle opines, is not technical.

What’s needed to create a useful ontology. Source: Kurt Cagle
Cagle also expands on what’s needed to create a useful ontology and whether upper ontologies are needed. Faith ranks and explains ontology property rules and M Bilal Ashfaq highlights the role of competency questions in ontology modeling.
State of the Graph unveiled the Graph Application Development category, including ontology and taxonomy tooling that defines the semantic structures applications run on. This is where knowledge engineers, ontologists, and domain experts work every day, long before a graph backed application ever reaches production.
In addition to established tools, we’ve seen a flurry of new releases.
Ontosphere is an open-source, browser-based OWL ontology editor with built-in OWL-RL reasoning and MCP support. Ontology Playground is a free, open-source web application for learning about ontologies and Microsoft Fabric IQ. SEMMweb is a new open source ontology editor. OrionBelt Ontology Builder hit v1.0.0. Competency Question Ferret is a free tool for tracking competency questions for ontologies.
State of the Graph
A comprehensive, up-to-date repository, visualization, and analysis of offerings across the graph technology space.

• Tech professionals exploring graph tools, platforms, and architectures
• Analysts and investors tracking market trends
• Vendors and builders seeking a clear, inclusive map to position their innovations
The LLM Wiki Pattern: From Personal Knowledge Graphs to Enterprise AI
The context graph principles seem to be converging on a design pattern that took the builder and tinkerer world by storm: Andrej Karpathy’s LLM Wiki. Most people’s experience with LLMs and documents looks like RAG, Karpathy argues. You upload files, the LLM retrieves relevant chunks at query time, and generates an answer.
This works, but the LLM is rediscovering knowledge from scratch on every question. Karpathy suggests a different architecture: Humans drive the judgment, strategy, and the hard questions. LLMs handle the heavy bookkeeping: updating knowledge, linking entities, maintaining system coherence.
Following the rise of the LLM wiki, systems that follow these principles emerged: Agent Lattice, Graphify, Hyper-Extract, OpenKB and Understand Anything to name just a few. Google introduced the Open Knowledge Format (OKF), an open specification that formalizes the LLM-wiki pattern into a portable, interoperable format.
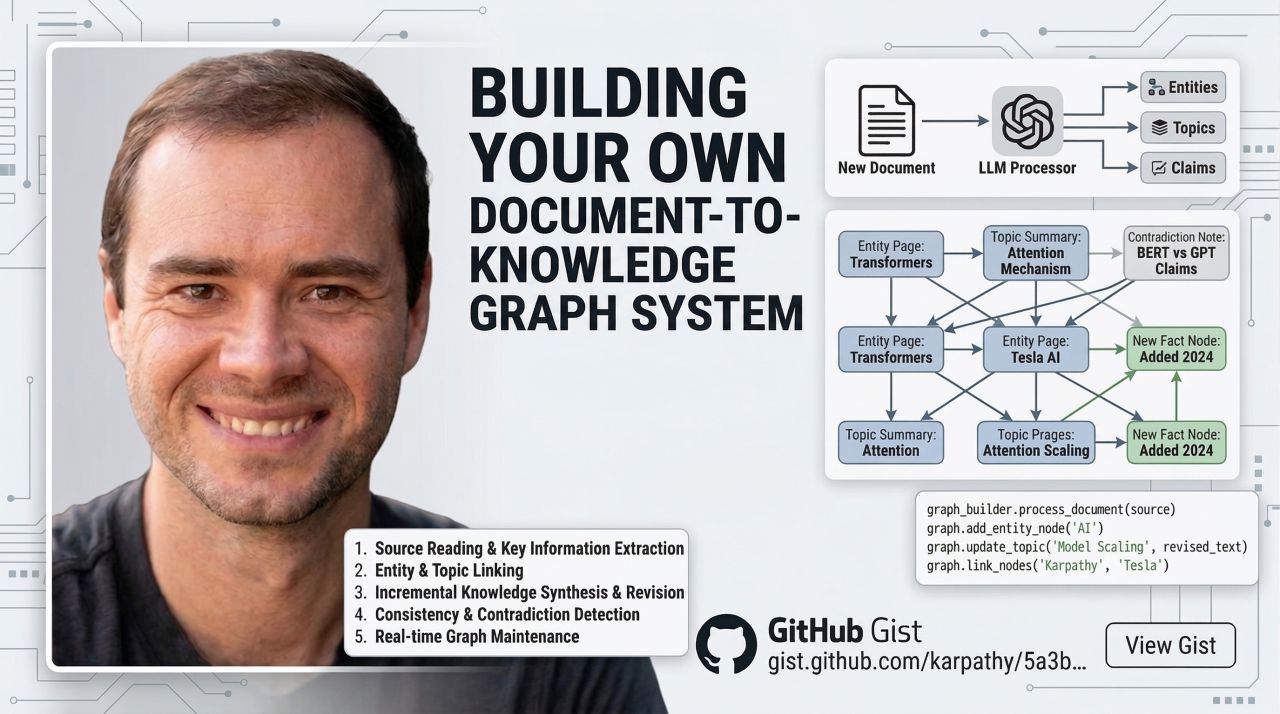
Andrej Karpathy’s LLM Wiki. Source: Daniel Chernenkov
In the LLM wiki, the wiki is just a git repo of markdown files. Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase. But here’s the question the graph community is already asking: is a Personal Wiki just a Knowledge Graph in disguise?
If you have nodes and links, you have a Graph. The flat .md file approach is elegant and simple to start – but at 10k+ nodes it hits an efficiency ceiling. Naive RAG as we know it is just a stepping stone. The future of AI isn’t just about faster answers. It’s about building knowledge that compounds. The graph layer is what makes it scale.
Tools like these are not just used by builders and tinkerers; there is a strong personal knowledge graph angle here. This is exemplified by Vivian Balakrishnan, Singapore’s Minister for Foreign Affairs, who has built an AI second brain to handle diplomatic complexity based on graph memory.
Knowledge Graphs, Memory and Context
The gap between frontier LLMs and real organizational intelligence isn’t about model size; it’s structural. Models are stateless. Context rots. Every session starts from zero. Vishakha Gupta’s Knowledge-Memory-Context blueprint maps AI cognition to how humans operate. The graph dimension is where the real divergence shows up.
The frameworks that handle full organizational scope – multi-tenant, multi-team, scoped permissions, audit lineage – do so through connected graph structures, not pluggable vector backends. The sharpest finding: pluggable multi-backend architectures are a performance trap at scale. Each handoff between an episodic store, a graph, and a session cache is a failure point and a consistency problem. Unified graph engines eliminate that.
State of the Graph is mapping a new frontier: how graphs are being used inside AI systems. GraphAI is the category where graph structure stops being passive infrastructure and starts doing active work, shaping what models retrieve, what agents remember, and what machine learning algorithms learn.
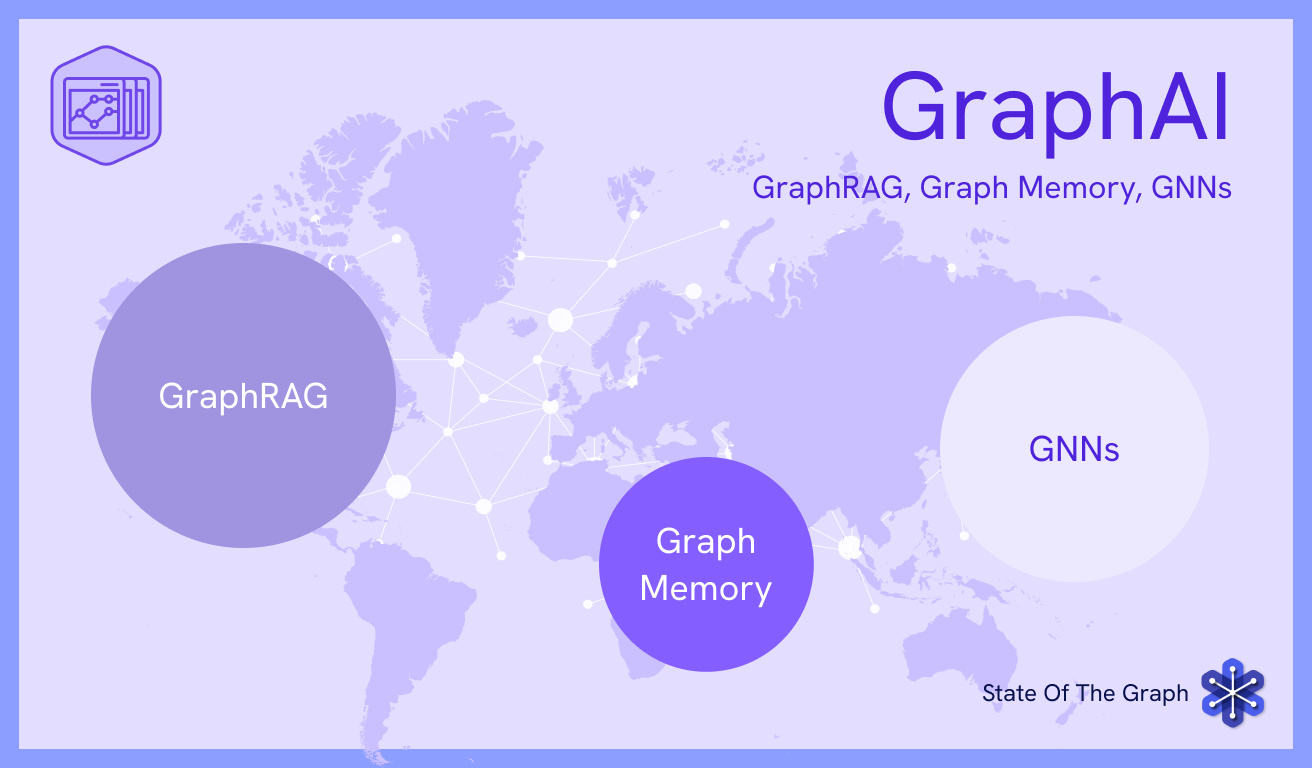
State of the Graph is mapping a new frontier: how graphs are being used inside AI systems
In GraphRAG, the graph sits in the retrieval path, selecting and grounding the context sent to a large language model. In Graph Memory, the graph organizes what agents know and have done, making long-term behavior inspectable and structured. In Graph Neural Networks (GNNs), the graph is the native input to machine learning itself, encoding relationships as a first-class signal for prediction and inference.
State of the Graph examines systems where graph structure is the architecture of memory, not just a data format sitting behind it. Entries in this type treat agents or agentic workflows as a primary target and provide long-term or shared memory that is explicitly structured as a graph, or as a hybrid of graph and vector representations.
Graph Memory substrates expose some form of trace or reasoning representation: decision graphs, graph-based histories, or visual flows of reasoning steps that make agent behavior inspectable. The emphasis is on platforms where graph-structured memory is a first-class design choice, not an afterthought bolted onto an orchestration layer.
Graph Memory Structure
As Anil Murty notes, memory is not RAG. RAG reads from a fixed external corpus. Agent memory is bidirectional: the agent writes facts during conversations, reads from memory to personalize responses, updates when facts change.
RAG for reference knowledge, memory for continuity. Murty distinguishes four useful categories for agent memory: short-term (in-context), long-term (persisted), semantic (what is true), and episodic (what happened, and when).
Artur Ciocanu reframes the problem: an agent’s memory isn’t a brain, he writes. It’s more like a customer data platform, where different agents are channels writing information about a person into a shared profile. Ciocanu traces a path for agent memory through three disciplines.
Computer science gives you excellent containers (databases, indexes, search) but no sense of what the data means or how it relates to other data. Cognitive science offered the idea of “episodic” vs “semantic” memory, borrowed from how human brains work. But human memory is reconstructive and a bit lossy. Agent knowledge needs to be the opposite: precise, versioned, and consistent.
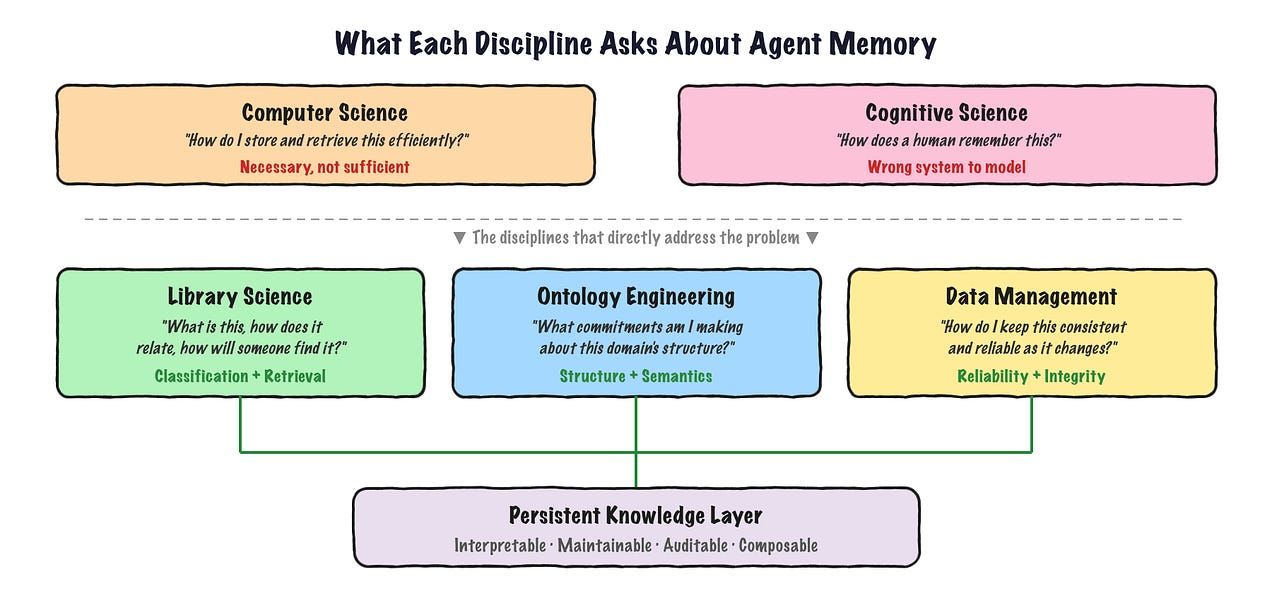
A path for agent memory through computer science, cognitive science, library science, ontology engineering and data management. Source: Artur Ciocanu
The third discipline is the unexpected one: library science, plus its close cousins, ontology and knowledge engineering. Librarians have spent over a century solving exactly this problem: how do you organize information so someone can find the right thing later, in a context you can’t predict in advance?
After auditing 20+ AI memory frameworks, Murty found that one structural insight keeps surfacing: the frameworks that handle enterprise-grade cognition aren’t the ones with the biggest vector stores. They’re the ones with graphs at the center. Case in point: BrowseNet, a graph-based associative memory for contextual information retrieval.
Andrea Volpini explored Structured Linked Data as a Memory Layer for Agent-Orchestrated Retrieval. He found that good graph memory makes agents answer more accurately with fewer steps. Daniela Pavlenco shows why graph traversal belongs at the heart of agent memory architecture.
Knowledge, Graphs, RAG, and Agentic AI
Graph Memory is one of the topics Anthony Alcaraz and Sam Julien cover in their book Agentic GraphRAG. Paul Iusztin also shares his take on Building Agentic GraphRAG Systems, and Emil Pastor shares how to architect and build graph-based agentic systems.
We’ve seen more GraphRAG use cases in Capital Markets, Cyber Threat Intelligence, Industrial Asset Operations, Legal, Finance, and Regulatory Compliance. Seyed Amir Hosseini Beghaeiraveri evaluates Codebase-Oriented RAG through Knowledge Graph Analysis, and Gitlab shipped GitLab Orbit, organizing codebases as a knowledge graph and SDLC as an ontology.
Shaiprashaanth Govindaraj benchmarked Standard RAG, KG Embedding RAG and Graph RAG. Dan McCreary and Dan Yarmoluk benchmarked Knowledge Retrieval architectures across 44 domains. Alex Mikhalev showed why Graph embeddings matter for RAG. Netflix built the Model Lifecycle Graph.
Clair Sullivan established entity resolved Knowledge Graphs as the foundation for effective GraphRAG. Irina Adamchic shared the Fixed Entity Architecture to make GraphRAG uncomplicated and nearly LLM-free.
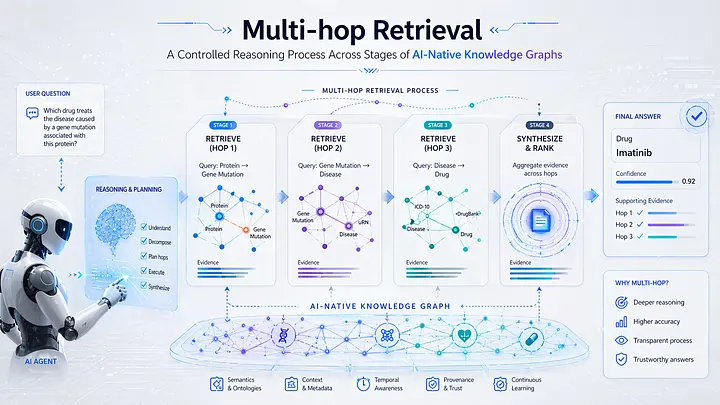
Multi-hop Retrieval: A Controlled Reasoning Process Across Stages of AI-Native Knowledge Graphs. Source: Fanghua (Joshua) Yu
Fanghua (Joshua) Yu wrote a series on GraphRAG, arguing that RAG is more than retrieval – it’s search & judge. Building on this, he offered a methodology for Knowledge Graph health assessment in terms of structure, entity and semantics, and completeness. These served as preamble to introduce Adaptive Graph RAG. In “Multi-hop Retrieval“, Yu addresses whether a graph database is really needed for RAG.
Cheney Zhang built a Graph RAG system without a graph database. Paul Iusztin advocates for a simplified GraphRAG stack, with unified memory over fragmented databases. But the Geometry of Forgetting proves that every vector database, RAG system, and embedding-based knowledge graph will eventually forget what you stored in it. Symbolic knowledge graphs won’t.
Two AI systems can both be called “RAG” while performing fundamentally different kinds of knowledge work; conversely, two systems can use different substrates while satisfying the same workload requirement. This mismatch makes architecture-centered labels a poor guide to capability. To address this, Gerasimos Xydas introduced Knowledge Operations: A Capability Model for AI Systems.
Graph Databases Become Graph Engines
Building architecture before you buy a graph database and start adding all your data in it as Josef ‘Jeff’ Heusserer argues is a fair point. Plus, you may be able to use something like DuckDB or Lance DB or even Postgres or SQLite to address your graph needs.
But that doesn’t mean that graph databases are going away. What this shows is that database vendors are aiming to provide graph functionality, and get a piece of a $2.85 billion market, projected to grow $15.32 billion by 2032, exhibiting a CAGR of 27.1% as per Fortune Business Insights. As for graph databases, they are evolving and solidifying.
Case in point: benchmarking Postgres against Memgraph. Besides demonstrating how native graph databases differ when graph workloads get real, Memgraph also serves as a showcase for graph database evolution.
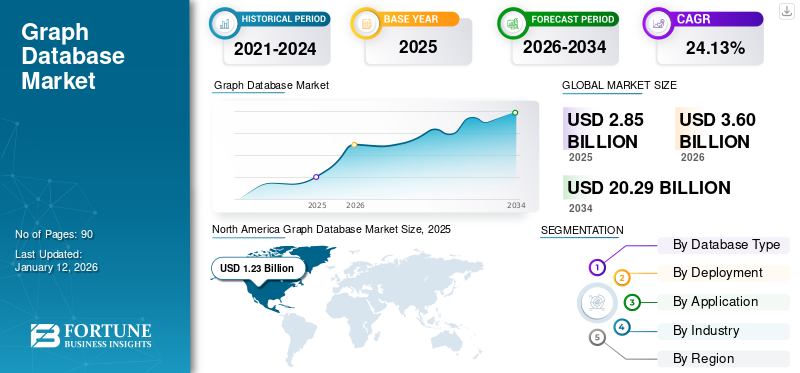
The global graph database market size is projected to grow from $2.85 billion in 2025 to $15.32 billion by 2032, exhibiting a CAGR of 27.1%. Source: Fortune Business Insights
Memgraph introduced Memgraph Zero, a product line built on the idea that data should stay where it is, and you should still be able to query it as a graph. In other words: a Graph Engine as part of a Graph Database offering.
“No pipelines. No ETL. No waiting for batch jobs before you can ask a question” is the promise, and the first product in that line, MemGQL, is available. MemGQL is a federated GQL query engine. It translates standard GQL into the native language of whatever backend, executes them in place, and returns unified results.
Neo4j announced its own graph engine product called Neo4j Virtual Graph, available in private preview. Virtual Graph lets you run Cypher queries and graph algorithms directly against the data you already have in Snowflake, Databricks, and other databases and lakehouses. Neo4j acquired GraphAware, expanding its footprint in intelligence analysis.
Graph Data Is Table Stakes: Why Meaning Is the Real Differentiator
Google may have popularized the term “knowledge graph”, but has abstained from the graph market in the sense of offering a dedicated product. Now Google is doubling down on graph capabilities and products, with its messaging centered around AI and agents. This is worth noting and interpreting.
Google announced graph support in BigQuery Conversational Analytics (preview), allowing agents to navigate a deterministic business map instead of raw tables to provide answers with higher accuracy. Google also announced the preview of graph algorithms with Spanner Graph, bringing Google Research’s state-of-the-art graph mining capabilities natively into an operational database.
What graph databases are doing by addressing operational aspects is just one part of the story. The most interesting part may well be the expansion of the total addressable market. This is happening mainly by repositioning; the new features and products are a by-product of the strategy.

Graph databases are necessary but not sufficient for enterprise AI. Source: Arango
And it’s not just Google: Stardog, a historical RDF graph database vendor, pivots to AI-oriented brand. RushDB 2.0 is pivoting from “graph database with batteries included” to a full memory infrastructure layer for AI agents and modern apps. FlureeDB v4 is positioned as “a secure context layer fit for autonomous systems”.
Fluree’s Brian Platz says “performance is table stakes”. Platz refers to Fluree’s benchmarks, but others are chiming in too. “Graph databases are necessary but not sufficient for enterprise AI. Modeling relationships in a graph database is not the same as managing business context“, as Arango’s Jakki Geiger and Ravi Marwaha put it.
Coming full circle, context is to AI what data was to BI – the raw input that allows the system to function. The thesis is that graph-based data models and substrates are the most appropriate to express and operationalize context. Graph data is table stakes. What matters is how the meaning of the data can be captured, shared and utilized.
Related posts:
 Graph is the new star schema. The Year of the Graph Newsletter Vol. 28, Autumn 2025
Graph is the new star schema. The Year of the Graph Newsletter Vol. 28, Autumn 2025
 Beyond Context Graphs: How Ontology, Semantics, and Knowledge Graphs Define Context. The Year of the Graph Newsletter Vol. 30, Spring 2026
Beyond Context Graphs: How Ontology, Semantics, and Knowledge Graphs Define Context. The Year of the Graph Newsletter Vol. 30, Spring 2026
 The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
The evolution of the graph technology and business landscape in 2025. The Year of the Graph Newsletter Vol. 27, Spring – Summer 2025
 The Ontology issue: From knowledge to graphs and back again. The Year of the Graph Newsletter Vol. 29, Winter 2025 – 2026
The Ontology issue: From knowledge to graphs and back again. The Year of the Graph Newsletter Vol. 29, Winter 2025 – 2026

